XDM/RD E2は、大量データを高速処理するための各種技術を備えています。
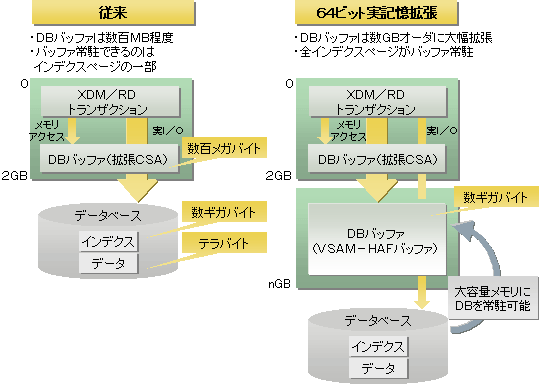
64ビット実記憶拡張によって、数ギガバイトオーダのDBバッファを使用できます。これによって、I/Oの回数を削減し、処理時間を短縮できます。データベース処理の大幅な高速化が望めます。
階層型DBでは、データの処理単位はレコードごとではなくレコードを構成する要素ごとです。リレーショナルデータベースでは、一般的には列単位でデータを操作する列インタフェースが基本ですが、列数が非常に多い表に対しては、列数に依存しない安定した性能を維持できる行インタフェースを利用できます。
繰り返し列とは、1行中の一つの列に複数の値を格納できる可変要素数の配列です。これにより、非正規形のデータでも効率よく格納・管理することができます。繰り返し列を使用すれば、従属するデータ数が定まらない場合でも、より自然な構造で扱え、表数を削減して検索時の結合を回避したり、行数を削減して行単位のオーバヘッドを回避したりできます。
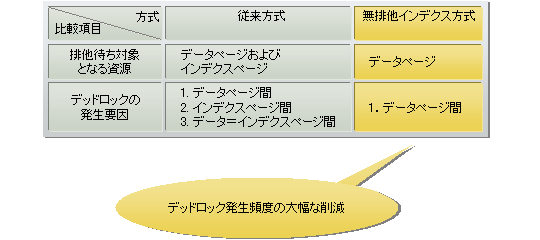
無排他インデクスとは、インデクスに排他制御を行わないで(データページまたは行に対しては排他制御を行う)、表の検索や更新などの処理を行う方法です。無排他インデクス表を使用することで、表検索中に行の追加、更新、削除などを同時実行でき、インデクスによる排他待ちやデッドロックをなくし、性能を向上できます。また、表だけでなく、インデクスの更新、検索処理についても、実行性能を向上します。
XDM/RD E2では、データベース処理を並列に実行することで、処理時間の短縮を図っています。並列実行できるのは、データの入出力処理、SQL実行処理、ソート処理です。
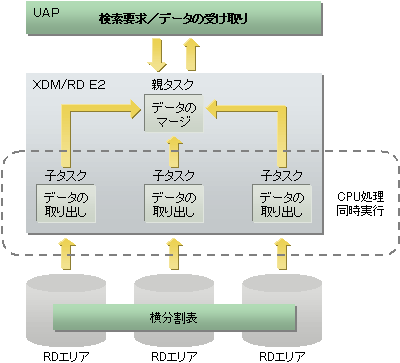
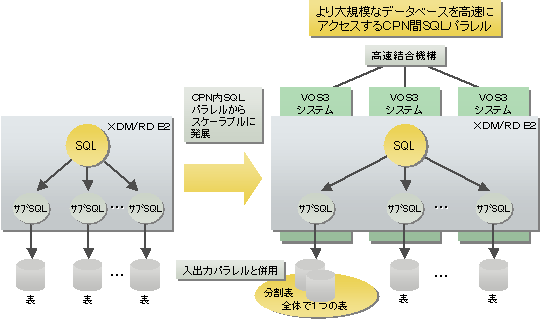
一つの表を最大1024RDエリアに分割し、その分割単位にユティリティを並列に実行することができます。これにより、ユティリティの実行時間の短縮や、分割単位にメンテナンスをするなどの運用ができます。
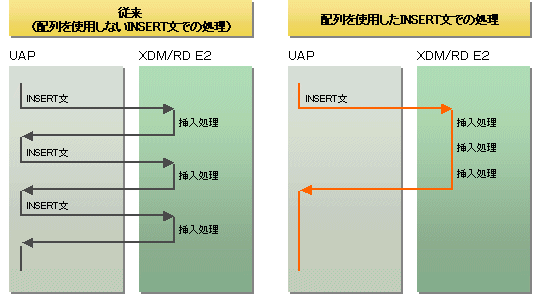
これまで、配列を使用したFETCH文を使用することで、1回のFETCH文で複数行の表データを受け取ることができましたが、今回、INSERT文、UPDATE文、DELETE文、およびEXECUTE文の更新値や検索条件に配列構造の埋め込み変数を指定することで、1回のSQL文で複数行分の表データを挿入・更新・削除できるようになりました。この機能を利用することで、UAPとXDM/RD E2間の連絡回数が削減できるため、CPU負荷の低減および更新処理全体の処理時間を短縮できます。