XDM/RD E2は、システムの大規模化、高信頼化、高性能化を実現するため、次の項目を中心に機能を強化してきました。
適用業務の変化によるデータベース容量の増加に伴い、RDエリア※の追加およびRDエリアを構成する物理エリアの追加(RDエリア容量の拡張)を業務中に行うことができます。
一つのRDエリアに格納できる最大データ容量は64ギガバイト、一つのXDM/RD E2システムに格納できる最大データ容量は128テラバイトを実現し、大容量データベースの構築が可能です。
また、XDM/RD E2では一つの表を複数のRDエリアに分割して格納できるので、一つのRDエリア(最大64ギガバイト)に格納できない大きな表を持つデータベースを構築できます。
大容量データベースの格納スペースを減らすために、データ圧縮をサポートしています。データ圧縮の手段として、XDM/RD E2が提供する標準圧縮拡張ルーチン、ユーザオウンコーディング、またはハードウェア圧縮が利用可能です。
オンライン系データベースとバッチ系データベースのグローバルバッファを分割して利用したり、インデクスを独立したグローバルバッファに割り当てることによって、業務に応じた効率的なデータベースアクセスを実現することができます。
大量検索、大量更新をする際、ローカルバッファを使用してVSAM一括入出力処理をすることで入出力回数の削減が可能です。また、ローカルバッファを利用することで大量検索・更新によるグローバルバッファの占有を抑止できるとともに、CPUの負荷を軽減できます。
UAPソースまたはSQLモジュールのコンパイル時、SQLオブジェクト(データベースへのアクセス手順を記述したオブジェクト)を作成することによって、データベースアクセス要求時のXDM/RD E2の前処理オーバヘッドを削減できます。
全件検索などでデータベースの連続したデータをグローバルバッファ上に読み込むとき、先読み一括入力(プリフェッチ)することで入出力回数の削減とCPUの有効利用が図れます。
この機能は、表およびインデクスのデータの格納順序が連続しているときに有効です。
UAPからのデータベースアクセス要求がデータの格納順に発生しているか、またはランダムに発生しているかを動的に判断し、先読みの継続/中断、および先読み一括入力ページ数を動的に決めて、効率の良いCPU・チャネル利用が図れます。
インデクスに対して作成しない任意のキー値(除外キー値)を指定でき、インデクス容量およびインデクス維持時のジャーナル量の削減によって、インデクスへのアクセス性能の改善が図れます。他のキー値の重複は少ないが、ある特定のキー値だけ重複が非常に多い場合や、ナル値が多い場合に効果があります。
XDM/RD E2では、データベース検索時に1件ごとにバッファの確保および解放をしています。この機能を使用すると、同じページから2回連続してデータを取り出したとき、1ページ分のデータを一括転送領域上に転送します。これによって、以降連続的にデータを取り出す場合にバッファの確保、解放が不要となり、検索時の性能が向上します。
表のデータを更新すると、インデクスも同時に更新されます。そのため、バッチUAPでデータベースを大量に更新する場合は、1件ごとにインデクス更新が発生し、性能が悪くなることがあります。インデクスの遅延更新を利用すると、インデクスを更新する代わりにインデクス更新情報をデータセットに取得し、その後データベース再編成ユティリティでインデクスを一括更新することで、大量更新時の性能を向上します。
FETCH文は、データベースからデータを1件取得するSQL文です。FETCH文のデータ受け取り変数として、配列構造の埋め込み変数を指定すると、1回のFETCHで複数行のデータを受け取ることができます。この機能を利用することで、UAPとXDM/RD E2との連絡回数(データの受け渡し回数)が減るため、検索処理全体の処理時間を短縮することができます。
XDM/RD E2で使用できるストアドプロシジャは、COBOL言語などで作った外部プロシジャに限定されていましたが、新たにSQL手続き文で定義できるSQLプロシジャおよびSQL関数も使用できます。さらに、SQLプロシジャやSQL関数の動作を記述するSQL手続き文も拡張し、本格的なストアドプロシジャ機能が利用できます。SQLプロシジャおよびSQL関数は、外部プロシジャと比べ運用や管理が簡単なため、UAPを効率良く開発できます。
トリガとは、特定の表に対する追加・変更・削除などのイベントを契機に、あらかじめ登録していた一連の操作を実行できる機能です。
例えば、顧客情報管理データベースの顧客データを追加・変更・削除した場合に、これを契機として自動的に変更履歴データベースへ変更情報を反映させることができます。この場合、変更履歴データベースに対して変更情報を反映するUAPを開発する必要がなく、システム開発・変更の負荷を軽減できます。
表作成時に参照制約動作を定義しておくと、被参照表での行の更新又は削除に対応して、整合性を保つよう、同じ値を持つ参照表の行を更新または削除できます(表間の整合性を保つ機能)。このことから、被参照表への操作に同期して実行していた参照表への操作を自動化できるため、UAPの作成負荷が軽減できます。
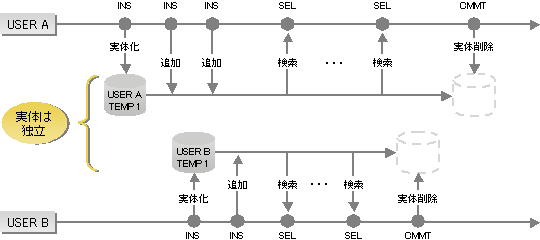
一時表とは、SQLセションまたはトランザクションの期間中だけ有効となる表のことです。このため、一時表に対して最初のデータを格納した時点で、そのSQLセションまたはトランザクション固有の表として利用できるようになります(定義しただけでは表として実体を持ちません)。
例えば、SAMなどの中間ファイルに書き出していたデータを、一時表に格納するようにすれば、SQLだけで業務処理ができるため、SQL言語の特徴を活かした、柔軟な業務設計が可能となります。
これまで参照制約は別の表の間で行う必要がありましたが、同一表内で参照制約ができるようになりました。参照制約とは、ある表のある列の値が別の列を参照するとき、参照される側の列の値が必ず存在しなければならないという制約です。この制約によって、参照関係がある表の間で、誤った値が格納されるのを防げます。
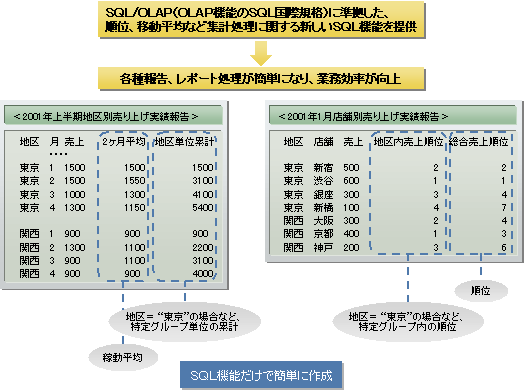
OLAP処理のための関数や集計範囲の指定などに関するSQL機能を拡張します。これにより、移動平均、順位や割合など集計・分析業務をSQLで容易に実現できるため、業務効率向上に貢献します。この機能はSQL標準化動向をふまえ国際規格SQL/OLAP仕様に準拠しています。