![]()

システムが高度化・複雑化する中で、業務がスムーズに進行しないときに、管理者がボトルネックを発見して対処することは、ますます難しい作業になっています。今回の運用講座では、BladeSymphonyによる障害発生時の自動対処の例をご紹介します。システム上のいずれかのサーバーに障害が発生したときに、自動的に予備サーバーに切り替えて起動する「N+1コールドスタンバイ」が適用されています。
業務スピードの低下に気付いたユーザーからクレーム。管理者がサーバー・ルームへ直行すると、なんとサーバー障害が発生!しかし、サーバー障害の原因の切り分けに手間取り、数時間を費やしてしまいました。
原因は、ハードウェアの障害に。そこで、管理者は障害サーバーを切り離し、予備サーバーをシステムに再接続。ソフトウェアをインストールし、動作確認。ここで配線のミスが発覚!再び作業をやり直します。
予想以上に時間がかかってしまい、障害対応に半日間を費やしました。結局、本来業務は翌日に持ち越しとなりました。
ハードウェア障害が発生していることを即座に自動検知。メール通知を受けた管理者は、サーバー・ルームへ向かいます。
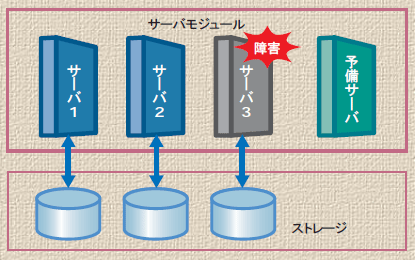
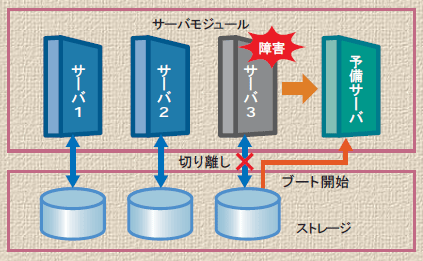
システムが自動的に予備サーバーへの切り替えをはじめます。障害の起きたサーバーを切り離し、予備サーバーに接続し直してブート開始。障害サーバーで動作していたOS、ミドルウェア、アプリケーションが予備サーバーで起動します。そして、業務が再開されました。
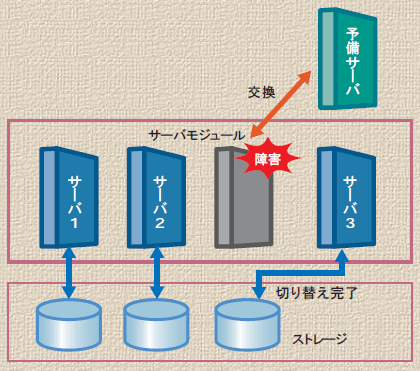
障害サーバーを別の予備サーバーに交換するなど、障害の後処置を速やかに実施。その後、本来業務に戻っていきました。
サーバー障害の対処は、熟練のオペレーターでも骨の折れる作業です。ましてや経験の浅い運用管理者であれば、焦りがミスを呼び、半日かかってしまうことも・・・。特にチケット販売システムのようにお客さまと直接つながるシステムであれば、損失も相当なもの。
その点、BladeSymphonyのN+1コールドスタンバイは、ストレージ側にOSやデータをすべて格納するSANブート環境で実行されるので、ソフトウェアの再インストール等の手間もなく、すばやく予備サーバーに切り替え可能。しかもこの作業はすべて自動化されており、オペレーションミスもなく、高信頼かつ高速に対処できるのです。さらに、1台の予備サーバーを複数サーバーの予備として共有して信頼性を確保できるため、システム全体の導入コストを最適化できます。
統合システム運用管理「JP1」ではさらにハードウェア障害以外の対処も自動化することができます。「監視」「確認」「判断」「対処」の4つのフェーズにおいて手順をルール化することで、システムだけでなくビジネス的な観点から総合的に判断し、自律的に対処できます。

