ビジネスでも日常生活でも、膨大なデータを扱うシーンが増えています。
ミリ秒単位で膨大なデータを処理できる「ストリームデータ処理」が、そんな時代のニーズに応え、いま注目を集めています。
日立は、この技術の可能性にいちはやく目を付け、10年以上前から研究開発に取り組み、製品化を実現しました。
ビッグデータという言葉が広がる以前から、データ処理のあり方を追究し続けた研究者のこだわりを紹介します。

今木 常之(いまき つねゆき)
主任研究員

西澤 格(にしざわ いたる)
プロジェクトマネージャ
(2016年12月1日 公開)
今木いまはIoTという言葉もよく耳にするようになり、例えば製造機器にもたくさんのセンサーが付いているような時代になっています。センサーで感知した温度や湿度のデータを監視して、値が異常だったときに、製造ラインを止めたり温度を下げたりする…そういった制御をする場合、大量に発生するセンサーデータをリアルタイムに処理する必要があります。1個のデータが入ったら、何ミリ秒、あるいは何マイクロ秒以内に処理できるかというところが肝になってきます。
今回紹介する「ストリームデータ処理」は、川の流れのように次々に入ってくるデータを、ストレージやデータベースに貯めずに、リアルタイムに処理していく技術です。

今木従来のデータベースを使用した処理の方法は、ストレージに入れたデータを対象にして、人間が命令(クエリ)を発行するという処理でした。例えば、製造機器のセンサーを監視して、平均温度が900度よりも上がった装置を検出する場合、1日分の装置の温度のデータをストレージに入れます。そのデータの中から、「平均が900度より高い装置があったか」という問い合わせに対する答えを出すという処理になります。
一方、ストリームデータ処理は、先に命令(クエリ)があって、そこにデータが入っていくというやり方です。直近の10件のデータの平均が900度を超えたときにアラートを上げるという条件をあらかじめ定義して、データの流れに対して、いわば罠を仕掛けておくんです。罠の条件にデータが引っかかったら、その瞬間にアラートを上げる。データが入ってからアラートを上げるまでを、1ミリ秒以下のような非常に短い時間で処理できることが特長です。
データベースを使用した処理が、ダムに水を貯めてから砂金をすくう処理だとすると、ストリームデータ処理は川の流れに網を張って、砂金が来たらその瞬間につかまえる処理と言えます。
西澤国内でこの技術を製品化しようとしたとき、最初に注目されたのは金融の業界でした。金融取引の場合、取引所が閉まったあとに1日分のデータを解析して、あとで取引するべきだった瞬間がわかっても意味はないですよね。ストリームデータ処理だと、取引する条件をあらかじめ登録しておけば、その瞬間に自動的に行うことができます。そういう使い方の違いがあります。
図1 データベースのデータ処理とストリームデータ処理の仕組み
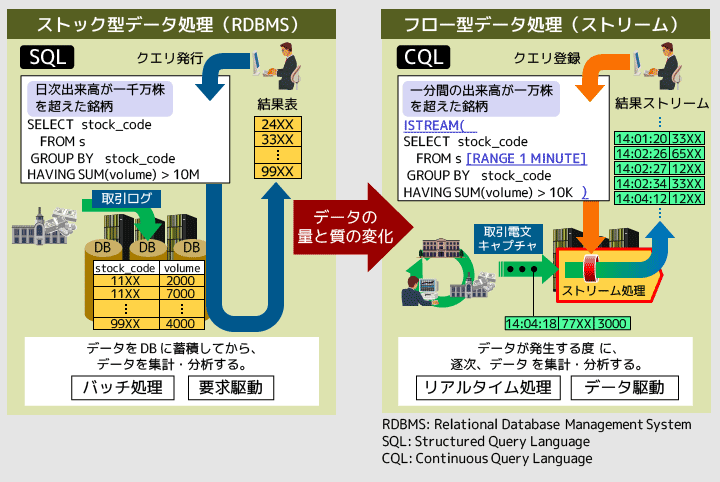
西澤メモリ上に展開されたクエリが、データを待っているというイメージが、基本的な処理の原理になります。データが入ってきてクエリを通ると、必要なデータはメモリ上で処理され、不要なデータは捨てられて、処理結果だけが出ていく。データがメモリ上にどんどん入っては消えていくという動作ですね。これには、古いデータを捨てていくことで、データの鮮度を保つという効果もあります。
今木この動きを実現するために、直近の10分、10件など、なるべく現時点に近いデータだけを「ウィンドウ」で切り取って解析対象を絞っています。この仕組みのことを「ウィンドウ演算」と言います。
図2 ウィンドウ演算の仕組み

今木さらに、ストリームデータ処理では、差分計算を取り入れることで、処理を軽くして、処理速度を上げる工夫をしています。例えば、ウィンドウに1万個のデータが確保されていて、その合計値を計算する場合、新しい10001番目のデータが入ってくると、1番古いデータが出ていきます。そのときに、2番目のデータから10001番目までもう一度足し合わせるということはしないで、出て行った1番目を引いて、10001番目を足すという計算の仕方をしている。合計値の計算はかなり単純な例ですが、join処理など、もうちょっと複雑な演算についても同様に処理できることが、ストリームデータ処理の特長です。
今木いかにレイテンシを短くするか、という点です。レイテンシとは、データが入ってから結果が出るまでの時間のことなのですが、実は当初、あまりレイテンシにはこだわっていなかったんです。それよりも、単位時間あたりの処理データ数、いわゆるスループットを高める方向で製品化に向けたプロトタイプ作りを進めていました。世の中の研究の方向も、スループット重視の方向でしたし。

西澤ストリームデータ処理は小さな処理の集まりなのですが、処理と処理の間にキューがあって、処理が追いつかない場合は、キューでデータを貯めておく仕組みでした。10個のデータがあったとき、それぞれ処理するよりも10個貯めて処理する方が、全体としては効率がいいじゃないですか。でも、キューでデータが貯まった場合、結果が出るまでに1、2秒掛かってしまうことがありました。ちょうどその頃、金融のお客さまからのご要望で、取引すべきタイミングになったときにどのくらい速く発注できるかという検証をしたのですが、「その考え方ではダメだ」と言われて。場面によってニーズは違ってくると思いますが、金融取引の場面ではスループットの高さよりもレイテンシの短さが求められるということで、処理方式をがらりと作り替えました。
今木製品化の直前の半月くらいで「レイテンシをどうにかしないと」という話になって、徹夜で対応したのを覚えています。愚直に、1つデータが入ってきたらそのデータをなるべく早く入口から出口まで処理する方法にすることで、ばらつきがなく、ミリ秒を切るぐらいの時間で処理できるようになりました。結果として、この件では特許も取得しましたし、社内で表彰もしていただきました。
西澤はい。2002年にスタンフォード大学で共同研究をさせてもらうことになって、研究テーマにストリームデータ処理を選んだんです。当時のアメリカでは、これからセンサーデータの可能性が高まるかもしれないということで、注目されていた研究分野でした。
その後、2003年に日本に戻ってきて、プロジェクトを立ち上げました。原理は持ち帰ったものの、日本でほぼゼロから作り直すという形でした。
今木西澤さんに声を掛けられて研究を始めたときは、日本ではまだビッグデータという言葉が広がる前の時代でした。当時は、ちょうどさまざまなデータが入ってくるということで、情報大航海だとか、情報大爆発だとか言われていましたね。わたしたちが着手したときが世界的な研究の萌芽期で、幸いなことに国内では日立が最初にストリームデータ処理製品を出荷できました。
西澤3、4人のメンバーでシステムのプロトタイプを開発し、実際にその上で動くデモを作ってアピールする期間がしばらく続いて、2008年にやっと製品化にこぎつけられたんですよね。小さく始まったプロジェクトでしたが、製品化のための部署もできて、数十人で製品を作っていくことになって…、そのときは本当に感慨深かったですね。

今木最近、ストリームデータ処理製品は、OSS(オープンソースソフトウェア)がたくさん出てきて、機械学習などの分析機能とパッケージングされているものも多くなっています。今後は、OSSと明確に差別化できる機能を作って、OSS用に作ったアプリケーションが、そのまま日立の製品でもっと高速に高信頼に動くといったことができると、ストリームデータ処理製品を作っている価値がさらに高まるのではないかと思っています。
西澤いまお客さまの状況も、研究を始めたときとは変わっているので、処理の速さをアピールするだけではいけないと思うんですよ。日立が掲げている「IT×OT」のソリューションとして位置付けるなどして、ストリームデータ処理基盤が強い部品となって、全体が伸びていく方向にいくといいと思っています。
今木この技術を研究している年数が長いので、まだ実装してないアイディアがたくさんあります。直近は、そういったアイディアを形にすることで、この製品のプレゼンスを上げて、ついでにわたし自身のプレゼンスも上げていきたいですね(笑)。具体的には、機械学習など高度な分析ができる基盤の開発をめざして、人工知能の技術などをいま勉強しています。
西澤わたしは、いまはお客さまと事業の協創を進める新しい組織に異動しているので、少し違う視点からの目標になってしまうのですが…。例えば、通信だとインターネットがそうでしたし、金融ではブロックチェーンがそうかもしれないと言われているのですが、いままでの業界の仕組みを変えてしまうような基盤となる技術の開発を、日本から主導・牽引しないといけないと思っています。

西澤スタンフォード大学での共同研究では、プロジェクト型の研究スタイルを体験しました。こういうプロジェクトをやります、と声を掛けると、そのテーマに興味のある学生がわーっと集まってくるんですよ。いろいろな国から優秀な学生が集まっていて、プログラミングが得意な人がシステムを作って実験をして結果を打ち合わせの場で示すと、その次の日にセオリーが得意な人が証明を持ってくる。実践と理論が組み合わさって、非常に早くものを作っていく、そのスピード感が印象に残っています。
さらに、非常にオープンな環境で、有名なベンダーの研究者がふらっと来てディスカッションに入ることもありました。日本の大学の研究室のスタイルとの違いを感じましたね。
日本も仕組みを上手く作って、世界で戦っていかないと。日本が標準のイニシアチブを取れるような、組織や人を日立の中で作っていきたい。いまは「これだ」と言える方法がまだ見えないのですが、そのためにどうすればいいかということを、いろいろ考えてトライしているところです。


