IT技術の進歩によって利用者の利便性が上がっていく反面、それを支えるITインフラは日々巨大かつ複雑になっています。これに伴い、ITインフラを運用管理する人々の業務負荷も高まる一方です。
これまでの単純作業の自動化だけでは、運用管理者の業務負荷は軽減しない—。そこで、日立では、いままで自動化が難しいといわれてきた「システムの障害対応」などの複雑な作業に焦点を当てて、自動化に乗り出しました。

永井 崇之(ながい たかゆき)
研究員

増田 峰義(ますだ みねよし)
主任研究員
(2017年5月26日 公開)
増田そうですね。扱うデータが増えてきたことで、管理しなくてはならない機器の台数は膨大になっていますし、仮想化などの技術によってシステムが複雑になったことで、運用管理業務の難易度は上がる一方です。それでいて、24時間365日これらのシステムを維持しなくてはならないのですから、もう人の力だけで運用管理することは事実上不可能です。このような背景から、「ITインフラの運用管理の自動化」という取り組みが盛んに行われるようになりました。
増田一口に「自動化」といっても、単純なものとそうでないものがあります。 単純な自動化の例としては、サーバやアプリケーションの起動・停止・再起動だとか、データのバックアップだとか、決まった時間に必ずやる定型的な作業が該当します。こういった作業は、一度処理を作っておけばあとはボタン一発で実行できるので、比較的簡単に自動化できます。
これに対して、いつ起こるかわからない非定型的な作業は、単純に自動化できません。典型的な例は、システムの障害対応ですね。すべての障害を事前に予見しておくことはできないので、その都度人の判断によって対策を考えなくてはいけません。
定型的な作業の自動化はすでに技術が確立してきているのですが、もはやそれだけでは巨大化・複雑化したITインフラは支えられなくなっています。障害対応のような、非定型的な作業にも踏み込んで自動化を進める必要があるのです。

永井具体的には、MAPEループというサイクルを回していくことになります。MAPEとは、Monitor(監視)、Analyze(分析)、Plan(計画)、Execute(実行)の頭文字です。常に問題がないかを監視し、問題が起きたら原因を分析し、どのように対処するか計画を立て、適切なタイミングで対処を実行する、という流れです。
このMAPEループのMonitor(監視)とAnalyze(分析)の作業の自動化を支援するために開発されたのが、Hitachi Infrastructure Analytics Advisorという製品です。
図1 MAPEループとHitachi Infrastructure Analytics Advisorのサポート範囲
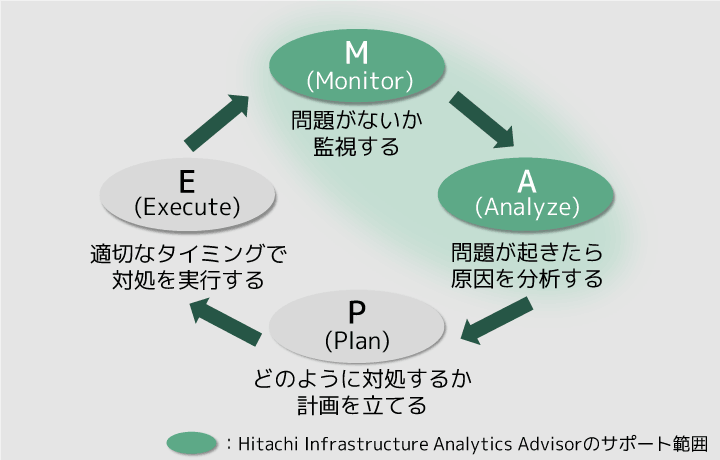
増田まず、Monitor(監視)の部分では、管理対象の機器から収集してきた膨大な性能情報を、見やすく可視化しています。システム構成の変更点や管理対象の機器で起きているイベントなど、全体の情報を1画面で見渡せるため、性能問題の有無を一目で確認できます。

Analyze(分析)の部分では、現在起きている性能問題の根本原因の特定をサポートしています。障害が起きるときって、問題が発生している機器自体にその根本原因があるとは限らないんです。別の機器の挙動が、意外なところで影響を及ぼしている場合もよくあります。
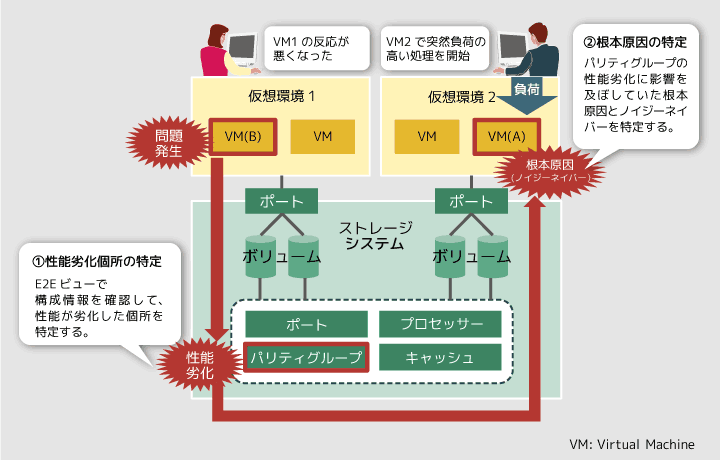
例えば、AというVM(Virtual Machine)が大きな処理を始めたことで、その処理を支えるストレージシステムの性能が悪化し、同じストレージシステムに接続しているBというVMのレスポンスが悪くなってしまうことがあります。この場合、VM(B)のレスポンス悪化の根本原因を作っているVM(A)のことを、ノイジーネイバーと呼びます。
システム構成が複雑になればなるほど、このノイジーネイバーの特定も難しくなってきます。Hitachi Infrastructure Analytics Advisorでは、E2E(End to End)ビューという画面を使うことで、このノイジーネイバーの特定がしやすくなります。
永井E2Eビューとは、複雑なシステムの構成情報を見やすく表示する画面のことです。従来は、根本原因を探すためにシステム上のコンポーネントを一つ一つたどって、それぞれの関係性を調べる必要があったのですが、E2Eビューを参照すればコンポーネントの関係性が1画面でわかるので、調査が非常に楽になります。
コンポーネントの関係性がわかると、問題の直接の原因となっているリソースと、その背後にある根本原因やノイジーネイバーも特定しやすくなります。
図2 E2Eビューを使ったノイジーネイバーの特定
増田はい、近年は管理する機器の台数が増えたことで、そのI/O負荷がストレージに掛かる傾向にあります。そのため、ストレージの性能問題が起きやすく、管理者の悩みの種になっています。その点、日立は長年ストレージ製品の開発を主力事業としていますので、ストレージの障害対応のノウハウが豊富にあります。Hitachi Infrastructure Analytics Advisorでは、そのノウハウに基づいて、どういった手順でどんなデータを見ていくと問題に行き着くのかを自然とガイドしてくれるようになっています。
永井ストレージの複雑なアーキテクチャを理解して自分で対処することは非常に難しいので、ストレージの障害対応を丁寧にガイドしてくれる点はHitachi Infrastructure Analytics Advisorの強みですね。
わたし自身もある程度ストレージ管理に携わってきた身ですが、それでも詳細な機能や挙動を理解することは難しいと感じています。実際の開発過程でも理解できないことが結構あって、そのたびにストレージのハードウェアを研究している人にヒアリングしていました。このような地道な情報収集によって、Hitachi Infrastructure Analytics Advisorには日立のストレージのノウハウが詰めこまれています。
増田管理者がどれだけスムーズに問題の原因へたどり着けるようにするか、ガイドのしかたに気を遣いました。先ほど紹介したノイジーネイバーの特定などは、その代表例ですね。これは現場の管理者から実際に聞いた話なのですが、システムの利用者が何の前触れもなく突然負荷テストを始めてしまって、それによって障害が起きたことがあったそうです。原因調査のために夜中に呼び出されたのですが、まさかそんな時間に負荷テストをしているとは思わなくて、その負荷テストをしている機器がノイジーネイバーだと突き止めるまでに非常に時間が掛かってしまったそうです。そんな管理者の苦労を、Hitachi Infrastructure Analytics Advisorによって少しでも軽減できたのではないかと思っています。
増田Execute(実行)については、自動実行に特化したHitachi Automation Directorという製品で実現しています。Plan(計画)については、実現に向けて現在検討中です。
このPlan(計画)というのが実はMAPEループの中で最も難しい部分なのですが、この部分の検討をメインで担当しているのが永井です。

永井ノイジーネイバーの特定によって原因がわかったのはいいけれど、じゃあどうやって対処していくのかという場面で、管理者が指示すると対処プランを提示してくれるという機能を検討しています。この機能の難しいところは、その場の状況に応じて、どのように最適な対処を導き出すかという点です。対処プランにも非常に多くの選択肢がありますので、それらをただ提示するだけでは意味がありません。状況に応じて最適な対処プランを導き出すためのロジックを作る必要があるのですが…これになかなか苦労しています。
実際、理論上はうまくいくだろうと思っていたのに、いざ対処プランを実行してみるとうまくいかなかったりして。そのたびにロジックを修正してまた実行する、という試行錯誤をしながら作っています。
永井はい。現在は、よく起きる問題や、特に対処が難しいといわれているストレージの性能問題に焦点を当ててロジックを検討しています。ただ、すべてのロジックを完ぺきに作ることはさすがに現実的ではないと考えています。我々開発者が作る対処プランには限界がありますので、将来的にはお客さまや製品の販売会社の意見を取り入れていきたいですね。例えば、お客さまが直接対処を入力できるようにするとか、お客さまと接点のある販売会社にヒアリングをしてその結果を取り入れるとか、我々が作ったロジックをみんなで拡張していけるような仕組みを作っていきたいです。すでに社内の関係者からは、「ぜひ我々も一緒にロジックを作りたい」と前向きな反応をもらっています。

増田そうですね。MAPEループが完成して、さらにHitachi Infrastructure Analytics AdvisorやHitachi Automation Directorの機能が充実して使いやすくなれば、だんだんと自動でさばける業務が増えていくでしょう。これによって、いままで苦労していた非定型的な業務の自動化が進んで、管理者の業務負荷が軽減されると思います。
永井ここ数年、わたしはHitachi Infrastructure Analytics AdvisorのようなITインフラの運用自動化に携わってきました。最近はITインフラもクラウド化によって設備を社外に出していたり、ハードウェアが高性能化してきたりしていて、取り巻く環境はどんどん広がっています。そのため、ITインフラという世界の問題解決だけではなく、ミドルウェアだったりアプリケーションだったり、ほかのレイヤーの問題についても対策していかないといけないと考えています。これまでITインフラの開発で培った知見や技術を、ほかの分野でも活用していきたいと思います。
増田わたしは、これからも現場の管理者の苦労が少しでも減るような製品を開発し続けていきたいですね。よく現場の管理者と実際にお話しする機会があるのですが、皆さんとても熱心に仕事に取り組んでいらっしゃいます。そんな人たちが日夜ITインフラを支えてくれているおかげで、いまの我々の生活が成り立っています。なので、少しでも現場の方々のお力になれるよう、これからも努力し続けたいですね。


