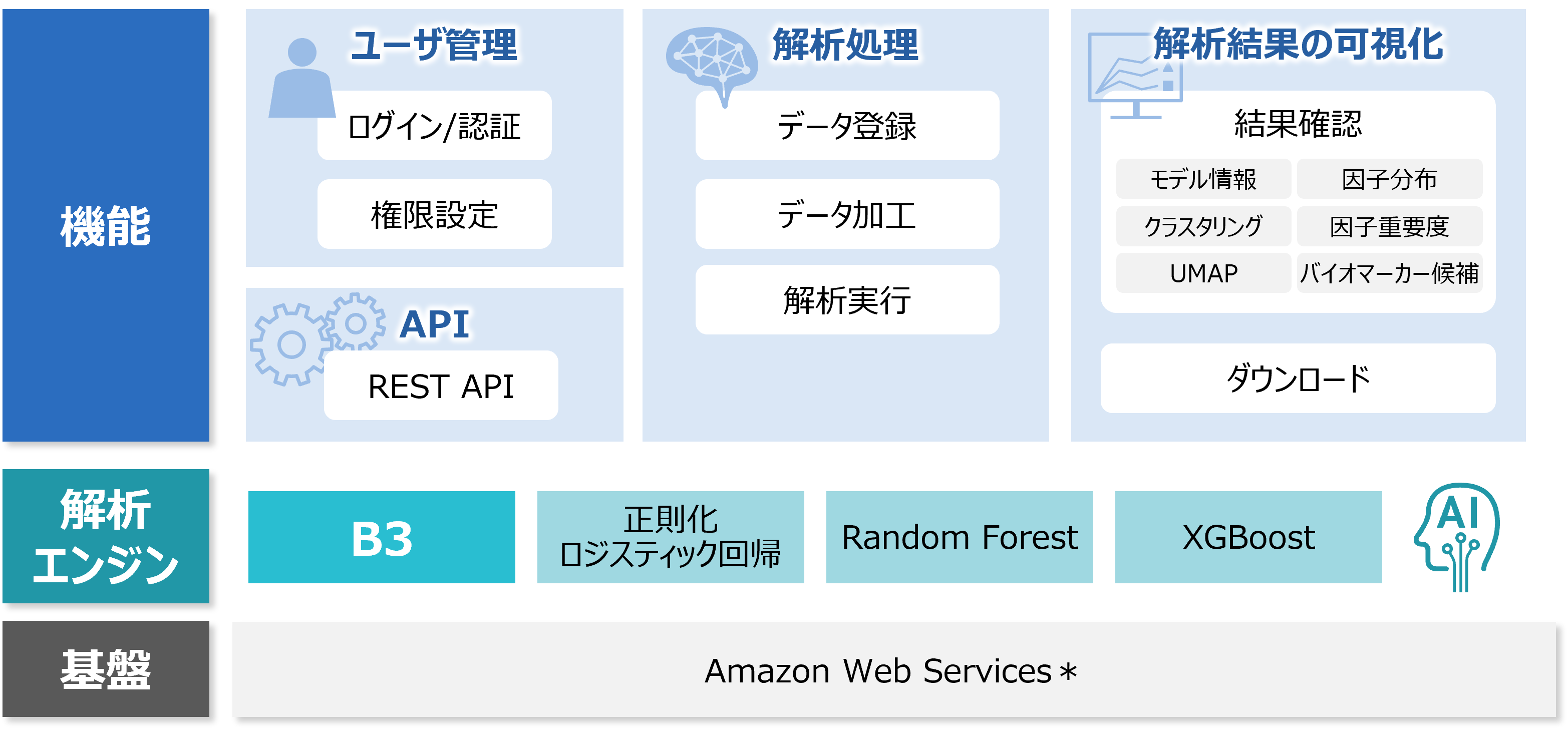
「B3 Analytics」の機能面の特長を紹介します。
複雑な生体メカニズムに対し、日立は2つのアプローチで説明可能AIを開発しました。
B3 Analyticsでは、シーンに合わせこれらの解析手法を選択できます。

ロジスティック回帰を用いて複数の直線を引くことで、非線形な事象を「直線」で説明します。

「高性能」「次元の呪いの回避」「医療統計との接続性」を兼ね備えた技術です。
オミックスデータではDeep learningベースのアルゴリズムよりも高性能であり、テーブルデータでもGBDT同等またはそれ以上の性能です。
局所線形関数近似により、B3内部で自然と次元圧縮がかかるため、特徴量が高次元であっても次元の呪いを回避でき、汎化性能も高くなっています。
局所線形関数の類似性が高い集団(サブグループ)は、線形関数で近似ができる集団であるため、B3が導出したサブグループを対象とした解析は、医療統計で実施可能です。

ロジスティック回帰で解ける「新たな因子」を作り出します。
因子と演算子の組み合わせを探索し、1つの数式として生成します。例えば「BMI値=体重(kg)÷(身長(m)×身長(m))」のような数式を組み立てます。
組み合わせの数は膨大になるため、強化学習を導入し、効率的にバイオマーカー候補となる数式を探索します。

どの機械学習手法も、学習用サンプルではAUC0.7以上ですが、検証用サンプルではB3以外の手法は精度が劣化していました。小サンプル・高次元データでの、B3の汎化性能の優位性を確認できました。

| 入力データ | 典型的な小サンプル・高次元データ サンプル数:200 説明変数: 3,000以上のオミックスデータ+臨床検査値 |
|---|---|
| 目的変数 | ある疾病の有無 |
| 検証方法 | サンプルを、学習用と検証用で分ける 学習用でモデル化、検証用で精度検証 |
B3 Analyticsは、B3による解析に特化したシンプルな機能・画面をご提供しています。
B3モデルにおける因子ごとの重要度(スコア)や、B3が保持しているサンプル毎の回帰係数を用いたクラスタリング結果を確認できます。

サンプルごとに保持している回帰係数(重み)の分布を、因子ごとに確認できます。
横軸:回帰係数(重み)
縦軸:サンプル数

アウトカムを高精度に予測可能な、因子の組み合わせからなる指標を自動生成します。

体験サイトでは、登録完了から30日間、B3 Analyticsをお試しいただけます。
AIを用いた高度な解析技術をぜひご体感ください。









