



人工知能(AI)の技術が進化し、現場での利用が広まっている。一方で、実際に活用していくと、人の知識や経験とAIの判断に乖離が起こることも少なくない。本当に現場で使えるようにAIを育てるにはどうしたらいいか。説明可能なAI(XAI)の視点から、先端AIイノベーションセンタの恵木正史主管研究員にAIの信頼性を高めるためにどのような技術が求められるのかを語ってもらった。
(2022年4月7日 公開)昔から物理や数学が好きで、それを生業にできるような職業に就けたらと考えていました。大学では工学部で固体物性の理論を研究していましたが、理論物理を追求したいと考え、大学院では理学研究科に移り宇宙物理の研究に取り組みました。難解な理論でも本質を理解して使いこなさなくてはならないので、ここで数理科学的な理解力や応用力が鍛えられたかなと思います。
就職に当たっては、それまで培ってきた数理科学的な力を生かして世の中の役に立てるような仕事を探しました。日立の中央研究所を見学したときに、「大規模な計算を必要とするようなデータ分析や可視化をやってみないか」と声を掛けて頂きました。今で言うデータサイエンスです。当時はまだそのような言葉はありませんでしたが、データ分析によって世の中の課題を解いていくという研究に興味を抱き、日立への就職を決めました。
また、日立が基礎研究からしっかりやっていることも魅力に映りました。基礎研究に力を入れている会社は少なく、また論文の執筆や博士号の取得なども奨励されていて、研究者を大事にしていることもわかりました。加えて、日立は幅広い分野で事業を展開しており、それだけ多くの分野での研究のチャンスがあることも日立を選んだ理由です。実際、日立にはさまざまな分野の専門家や研究者がいて、異分野のメンバーとの議論やコラボレーションがとても盛んなのです。
入社当初はWebサイトの応答性能を分析する研究に携わりました。応答性能が悪いとサイト訪問者は去ってしまうので、Webサイトの運営者は応答性能を上げなくてはなりません。そこで、サーバに記録された膨大なログデータから、応答性能向上のボトルネックを分析する研究を行っていました。その後も、気象、株価、電力、遺伝子、人間行動などさまざまな分野のデータサイエンスの研究に取り組んで来ました。例えば、気象分野では、天候によって業績が左右される企業向けの保険商品「天候デリバティブ」の保険料金を過去データと気象庁の長期予報から合理的に算出するシステムを作りました。当時この取り組みは新しく、これまで日立と取引がなかった企業にも売れました。このプロジェクトには天候デリバティブの専門家がいらっしゃったのですが、「誰でも入手できるような気象データと知識とを融合することで、大きな価値に変換できる」ことを、身をもって知りました。

一方で、こうしたデータサイエンスの仕事をする中で感じていたのが、開発した分析手法が理論的に妥当というだけでは、現場の専門家には納得して頂けないということです。分かり易い原理から説明したり、学術的に認められている理論に基づいている点を説明したり、分析結果が既知の事実と整合している点を説明したりして納得感を持ってもらうことが重要なのです。
その後、事業部に移動し2012年に「データアナリティクスマイスターサービス」の立ち上げに関わりました。ビッグデータ利活用のコンサルテーションを提供するサービスで、これまで取り組んできたデータサイエンスのプロセスをまとめて1つのサービスとして提供する体験を得ました。研究所としての仕事に加え、事業部のアクティビティや仕事の進め方を学ぶことができたのはありがたかったです。
その後、研究所に戻って、メンタルヘルス、スポーツ科学、脳活動、歩く際の身体運動をみる歩容解析などの生体計測分野のデータサイエンスに携わりました。生体計測のような多次元の複雑な時系列データから意味を抽出するためにAI技術を利用していましたが、現場の専門家に納得してもらうためには、AI判断の妥当性やその根拠を説明することが課題だと感じるようになりました。当時はまだXAIという言葉もなく、AIの判断傾向を支持するような論文を探して妥当性を主張する方法を検討していました。しかし、すべての分野に豊富な論文があるわけではありません。もっと別の方法で根拠を説明する必要があると感じていました。このような課題意識から、AIの判断を説明する技術に取り組み始めました。
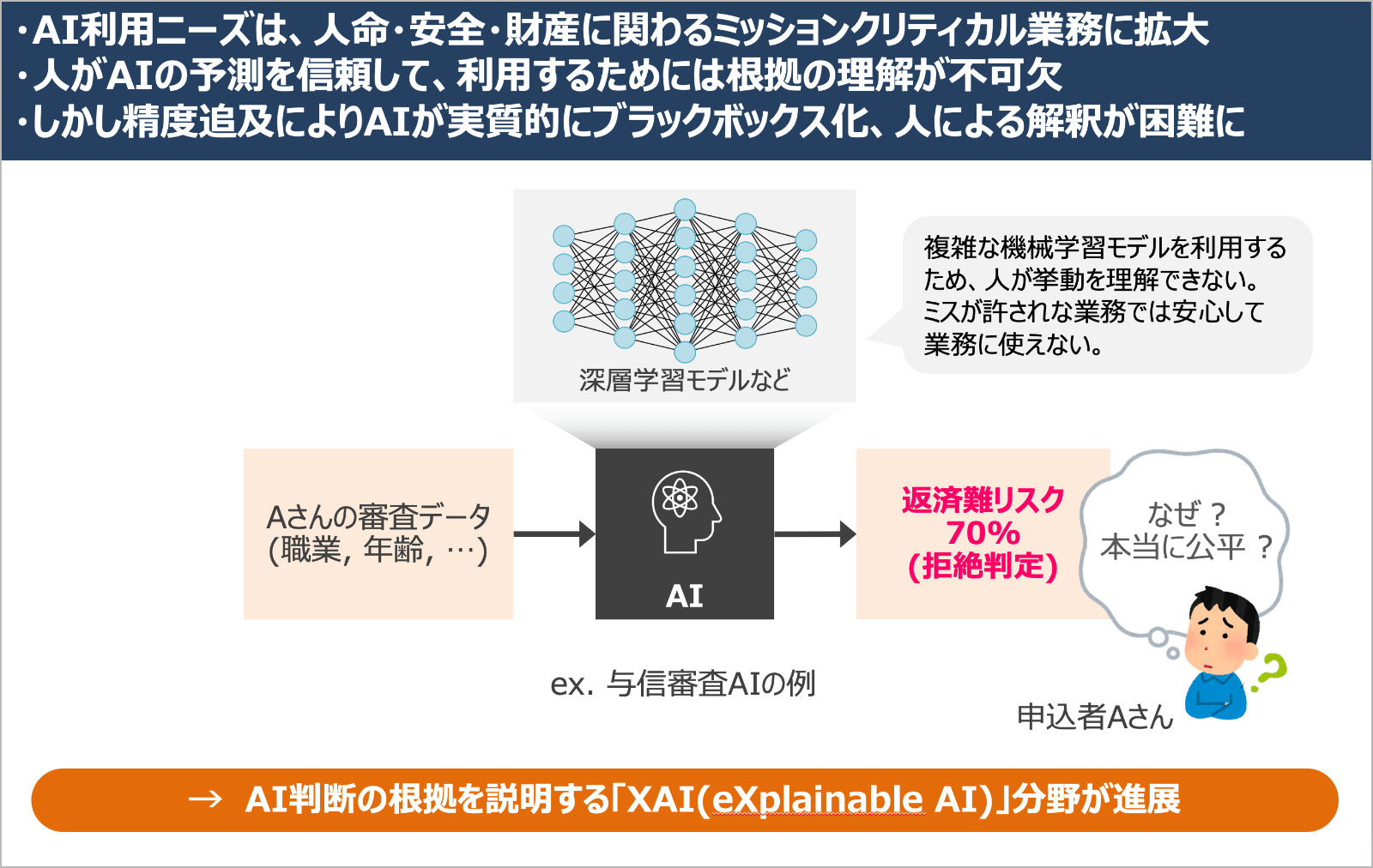
2017年、米国防総省の国防高等研究計画庁(DARPA)が「説明可能なAI」(XAI、Explainable AI)のプロジェクト を立ち上げました。数年にわたる研究計画で、さまざまな観点からのアプローチが研究されることを知り、非常に興味を惹かれました。このプロジェクトを1つの契機にXAIに関する数多くの学会が開かれ、重要な技術が毎週のように多数登場するようになります。
AI技術が目的や対象データ(テキスト、画像など)に応じて多種多様であるように、XAI技術も説明の観点や対象データに応じて多種多様です。つまり何か単一のXAI技術があれば万能という話ではないわけです。XAIは技術のポートフォリオとして捉えるべきだと考えています。実際、日立では複数のチームがXAIの研究に取り組んでおり※1)、私のチームもその1つという位置づけです。
さて、XAI技術は大きく2つのタイプに分類できます。1つは、AI内部が複雑でわかりにくいブラックボックス型AIを対象に、AIがなぜそのように判断したかを説明する技術です。もう1つは、最初からAI内部が人にとって解釈しやすいように作るトランスペアレント型AIの技術です。また説明の観点も、どの因子を重視したか、どの過去事例を重視したかなど複数の観点があります。加えて説明対象であるAI技術そのものも多くの種類があります。そのため膨大な数のXAI技術が提案されています。こうした数多くの技術の中から、真に有望な技術を目利きし、それらを実際にビジネスに適用するときに生じるギャップを解決していくことが大切だと考えています。
こうして開発した技術の1つが多角的診断技術です。一言で表現すれば、AI用の人間ドックのようなもので、ブラックボックスAIに適用することで、AIが何を根拠に考えているのか、どんな場面でその判断は信頼できるかなど、さまざまな観点からAIの頭の中を診断することができます。この技術は、2020年に提供を開始した「XAIを活用して業務システムへのAIの適用や継続的な運用・改善を支援する『AI導入・運用支援サービス』」の中で活用されています。
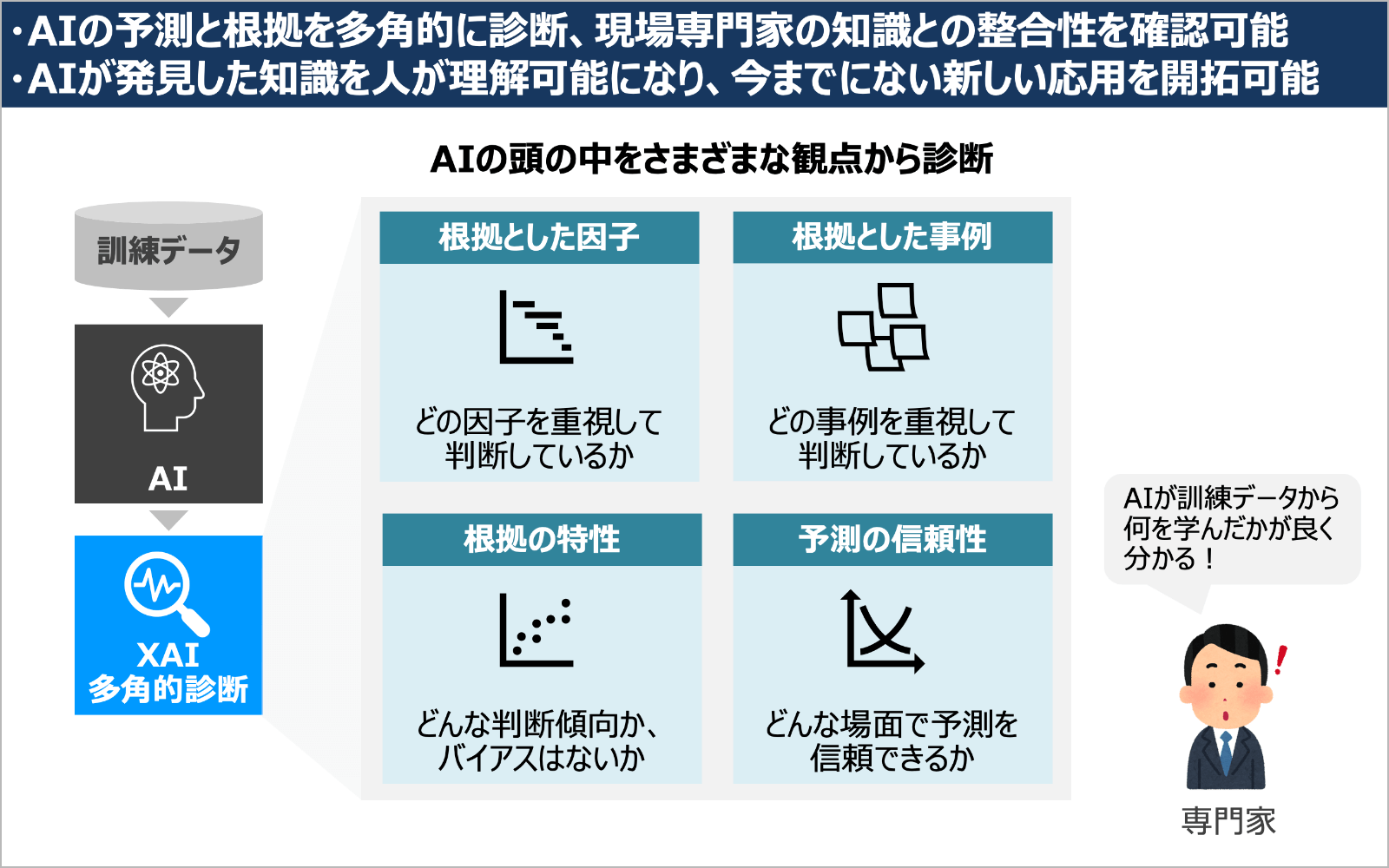

AIは学習時に訓練データの中から、判断の拠り所となるパターンを知識として発見し、それに基づいて判断しています。XAIを使うことで、AIの頭の中からそのような知識を、人が解釈できるような形で抽出できるようになりました。しかし、ここで新たな問題が生じました。それは、AIの知識と専門家の知識とが整合しない場合があるということです。AIは訓練データから知識を学び、専門家は長年の経験から知識を学んでいます。いったいどちらが正しいのでしょうか?
例えば、コンクリートの強度をセメント量、水分量や経過日数から予測するAIを考えます。専門家は、セメントの量とコンクリートの強度が正比例の直線的な関係にあることを経験から知っているとします。しかしXAIでAIの頭の中をのぞいて見ると、両者の関係がグニャグニャした曲線になっていることが分かったとします。すると、それを見た専門家は「このAIは本当に信頼できるのか?」と疑問に思うことでしょう。実際、このようにAIの知識と、専門家の知識とが整合せず、問題になった場面に何度も遭遇しました。
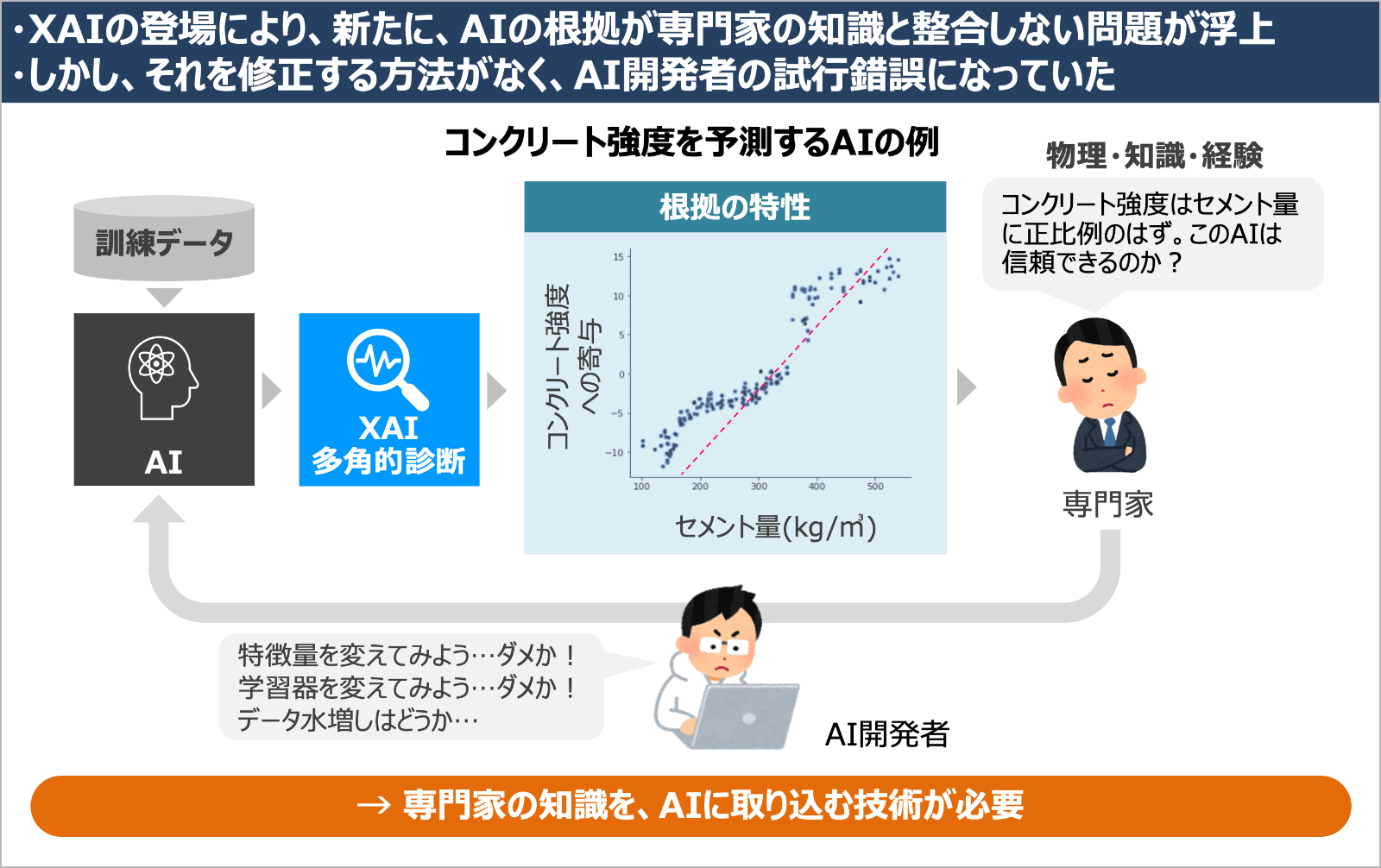
さらに別の問題も発生しました。学習条件を変えてAIを作り直すと、先ほどのグニャグニャした曲線が変化しているのです。言い方を変えると、同じような精度のAIであっても、予測結果や根拠が異なるAIが無数に存在しうるわけです。この現象は、黒沢明監督の映画「羅生門」になぞらえて「羅生門効果:Rashomon effect」と呼ばれています。映画の中では、殺人事件に対して、複数の登場人物が異なる証言をして、捜査が行き詰まってしまうエピソードがあります。同じように、我々もどのAIの言い分が一番正しいのかがわからないのです。
どうしてこのような現象が生じるのでしょうか? AIが学ぶ訓練データの中には無数のパターンが潜在しています。有意なパターンもあればあまり有意でないパターンもあります。またパターン同士が複雑に関係している場合も多い。AIは学習の過程でこれらを取り入れながら予測精度を高めて行きます。すると、同じような予測精度を示すAIなのに、学習条件のわずかな違いによって、予測の拠り所であるパターンが異なるAIが何通りもできあがってしまうのです。このような現象は、訓練データが十分でない場合に特に顕著になります。
この問題に対して、私たちはこの羅生門効果を逆手にとれば、AIと専門家の知識の不整合を解決できることに気が付きました。つまり、根拠の曲線が異なる多数のAIを集め、それらを適切に重みづけして合成したAIを作れば、専門家が考える根拠の曲線に近づけることができるわけです。我々はこれを「根拠校正技術」と呼んでいます。
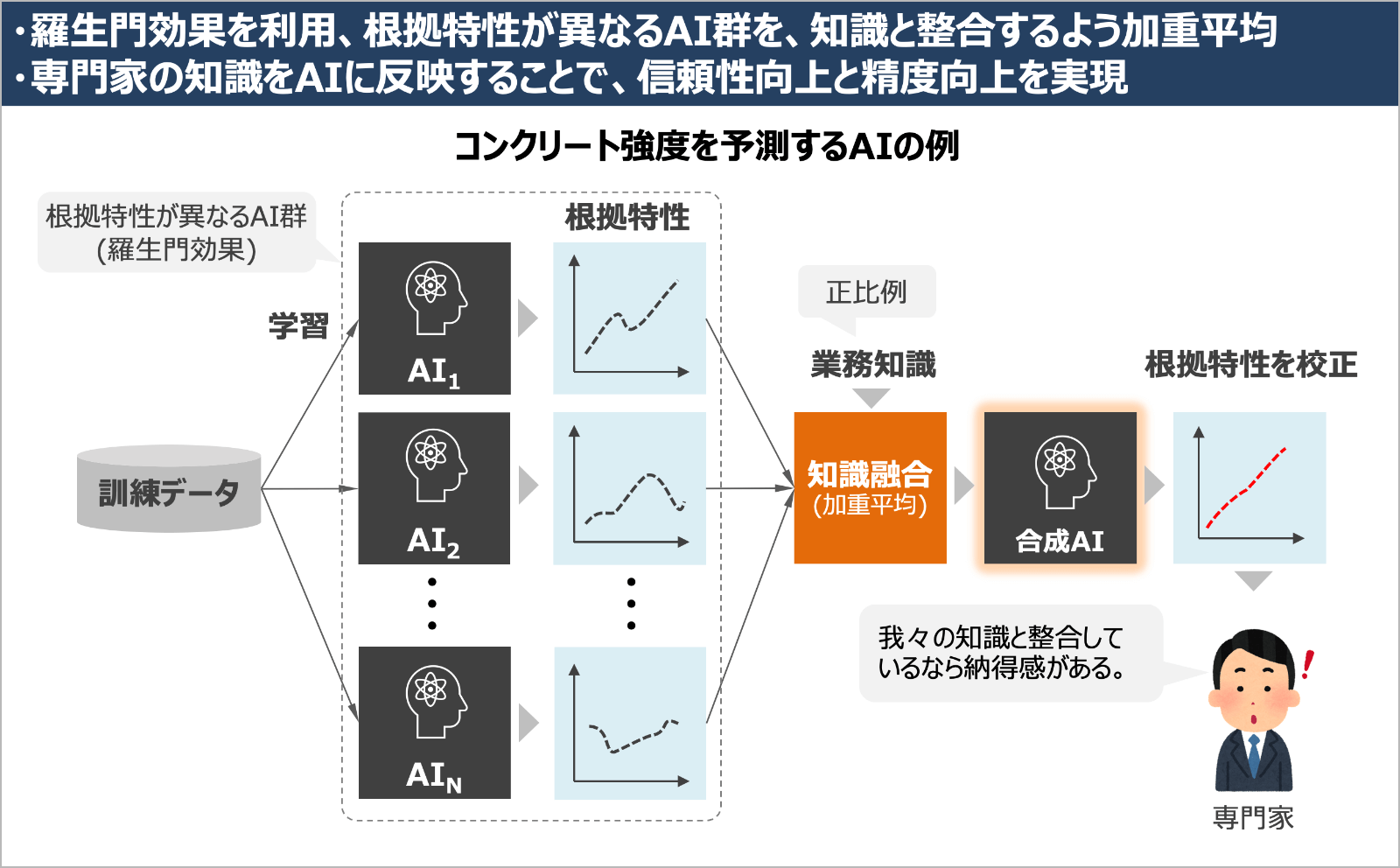
この技術により、AIの知識と専門家の知識の良いとこ取りができます。AIは訓練データの中から知識の候補を網羅的に抽出することができます。そこには専門家も良く知っている知識もあれば、新たな発見もあると思います。その中で、専門家の知識と照らし合わせておかしいという部分があれば、そこだけを校正することが可能です。言い方を替えると、専門家の知識をAIに教えることができるわけです。
この技術は、専門家の納得感を高めることにも貢献しますが、同時に、専門家の知識をAIに教えることで、予測精度の向上も期待されます。実際、先程のセメントとコンクリートの例では、セメント量とコンクリート強度の関係の根拠が正比例に修正されたことで、誤差が8%改善する効果が見られました。
この技術を使って、JR中央線の国立駅に隣接するショッピングセンター「nonowa国立」で実証実験をしました。買い物客の人流などのデータと、現場有識者の知見を取り込み、売上貢献度を推定したのです。ここで有識者の知識を使ってAIを校正すると、良いAIができただけでなく、現場の方の納得感が高まることがわかりました。
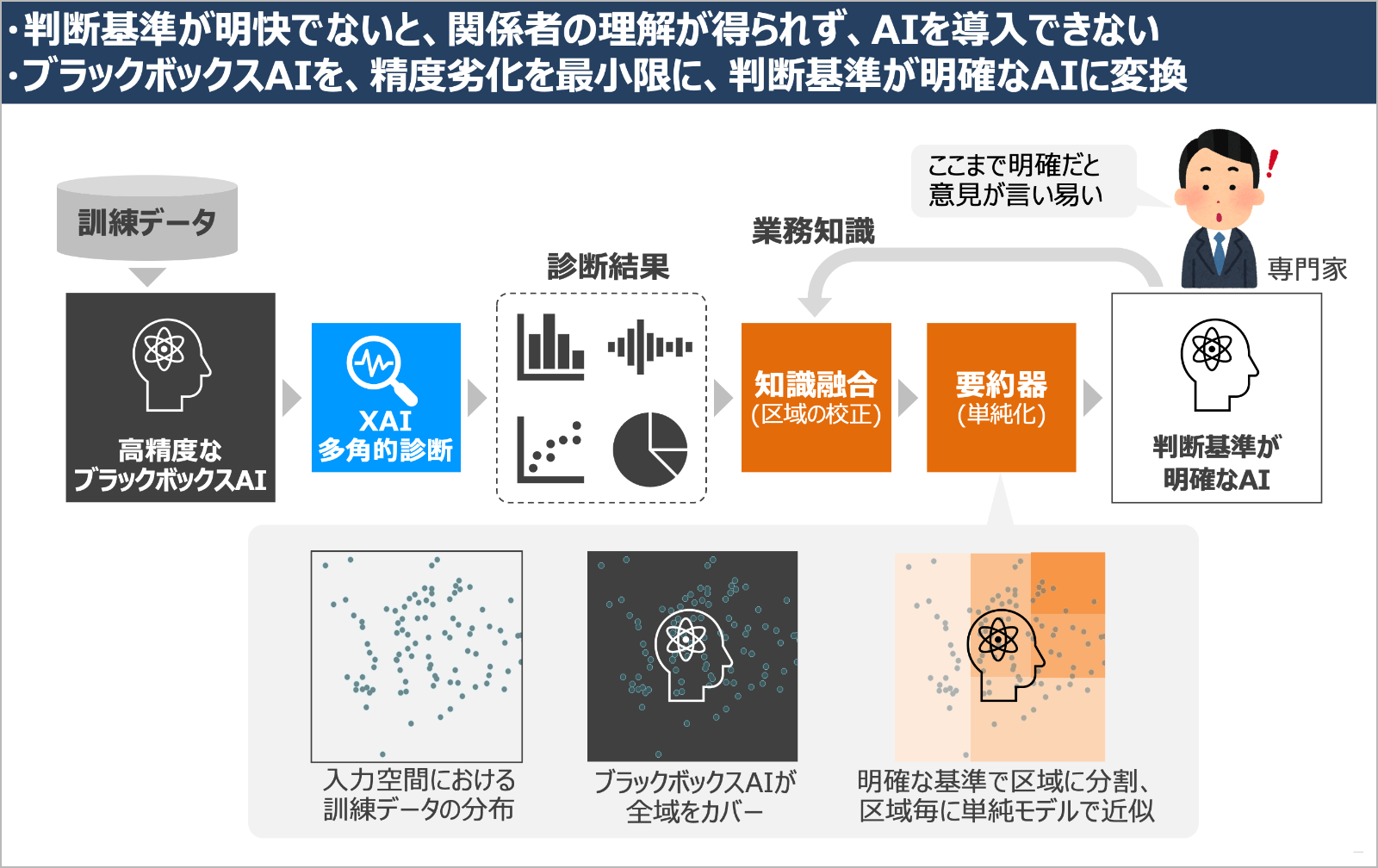
もう1つ、XAIを活用して開発したのが「単純化技術」です。この技術は、高精度だけれど複雑なブラックボックスAIを、判断基準が明確なAIに変換することができます。AI導入のニーズはさまざまな業務に拡大していますが、中にはAIの判断を自動的に採用するような検品やインフラ制御などの業務もあります。そのような業務では、XAIで説明するだけでは足りず、AIの判断ロジックが人から見ても一目瞭然であることが求められます。単純化技術はこのような場面での利用を想定して開発されました。
単純化技術では、まず一旦、高精度だけれど複雑なブラックボックスAIを作ります。これを多角的診断技術にかけることでAIの頭の中がわかります。その診断結果をもとに、要約器が、ブラックボックスAIの複雑な判断ロジックを、人が理解できるレベルに自動的に要約する仕組みです。より具体的には、XAIによる診断結果をもとに、入力空間を幾つか区域に分割して、区域毎に人が理解できるような単純なモデルでブラックボックスAIを近似します。
深層学習などで作成されたブラックボックスAIは精度が高い代わりに、膨大な数のパラメータを含んだ複雑な数学的構造物で、人がその判断ロジックの全容を理解することは到底不可能です。しかし、我々の要約器を通して単純化することで、精度劣化を最小限に、少ないパラメータしか持たない、判断基準が明確なAIに変換することができるのです。
この技術は2021年12月に国際学会で発表しました。発表の中では、ブラックボックスAIと同程度の精度を保持しながら、パラメータの数を数十万から数十程度まで単純化することができた事例など、この技術の詳細を報告しています。
また、AIの判断ロジックが明確になると、現場の専門家が判断ロジックについて具体的に口出しできるようになり、納得感向上と精度向上の好循環が生まれます。実際、日立グループのある検品業務の現場では、このようなプロセスを経て、我々のAIが本番システムとして稼働しています。
説明性の観点から「信頼できるAI」を実現するには、AIの知識が現場の知識と整合していることを確認して頂くことが大事だと考えています。そのためには、現場の方々に知識や経験を語って頂く必要があるのですが、具体的に言葉にして列挙して頂くのは簡単ではありません。
ここでXAIを使うことで、「このAIは訓練データからこんな知識を見つけて、判断に利用していますが、これまでのご経験から妥当性はどうでしょうか?」と質問することができます。すると、「これは経験と合っている」「これは経験と合わない。経験的にはこうなっているはず」「この閾値は物理的にはもう少し低いはずだ」「これは意図しないバイアスなので、取り除かなくてはならない」など、具体的な意見を言いやすくなると思います。
こうして明らかになったAIの知識と現場の知識のギャップを、今回ご紹介した根拠校正技術や単純化技術などを使って改善していくことで、現場の方々がAIへの理解を深め、AIへの信頼感が醸成されていくと考えています。AIを作るのに、現場の知識をフィードバックする必要があるというのは面倒と感じられるかも知れませんが、現場から信頼されるAIを実現するには、こうしたプロセスが大事だと思います。
また、信頼できるAIには、今日お話しした説明性だけではなく、品質、公平性、プライバシー保護などの複数視点からの要件も関わってきます。日立ではこれらの研究も精力的に進められています。これらの要件に対応するということは、診断の結果「要件をどう満たさないのか」という「AIの症状」を明らかにして、それに対して有効な「改善策」を講じてAIを治すこと、と解釈すると分かり易いと思います。今日ご紹介した技術も、AIの知識と専門家の知識との不整合、という症状が露見した場合の改善策の1つとして位置付けることができます。今後、信頼できるAIの実現のためには、こうした改善策を拡充していくことも大事だと考えています。

恵木正史(EGI Masashi)
日立製作所 研究開発グループ本当にお世話になったなあ、と実感する書籍は、大学時代から愛用してきた「岩波 数学公式(全三巻)」(岩波書店、森口繁一、宇田川銈久 一松 信著)です。正直、こんなに長く使い続けるとは思いませんでした。AIを含めたデータサイエンスの研究では、まずは研究者が理論の前提条件を正しく理解している必要があります。データサイエンスの技法は基本的に単なる計算方法なので、前提条件を破って使っても、何かしら計算結果は出てきます。しかし、その値の妥当性や信頼性には疑問が残ります。特に分析結果に基づいて重要な意思決定をする場面では、これは深刻です。このような問題を回避するためには、研究者は技法の導出過程を、責任感を持って確認する必要があるのです。実際、論文には書かれていないけれど、重要な前提条件があった、という場面に遭遇することもしばしばあります。このような仕事の中で、この公式集はいまだに重宝しています。
*1)
ヘルスケア分野:
画像分野:
2020年度情報処理学会論文賞「Deep Neural Networkのモデル逆解析による識別根拠可視化技術(情報処理学会のWebサイトへ)


信頼できるAIには、説明性に加えて、品質、公平性、プライバシー保護などの複数視点からの要件も関わってきます。日立では様々な部門でこれらの研究も精力的に進められていますが、これらの要件に対応するということは、「AIの症状」を明らかにして、それに対して有効な「改善策」を講じてAIを治すことだと考えていただけると良いかもしれません。