山本オープンデータを効果的に活用するためには、異なる分野や組織から提供されるデータを組み合わせて利用できることが重要です。しかし、本来同じ種類のデータなのに、分野や提供元の組織ごとに用語の表記(項目名)や構造が異なってしまっていて、活用しづらいという課題があるのが現状です。例えば、同じ氏名のデータでも、「氏名」という項目で一つにまとめているデータ、「名前」という異なる表記を項目名として使っているデータ、「姓」「名」という二つの項目に分けているデータなどが存在しています。このような状態だと、複数の分野や組織で提供される氏名のデータを組み合わせて利用したくても、そのままでは利用できません。データの表記を統一したり、二つに分かれているものを一つにまとめ直したりする、という手間が掛かってしまいます。これだと、オープンデータを活用したい人にとってはとても不便ですよね。
山本用語の表記や構造が異なっていても、それが同じ意味の用語として解釈できるようになれば、利用しやすくなりますよね。さらに、各用語の表記や構造をみんなで「共有」できれば、このような問題も発生しなくなります。こうしたことを実現するための仕組みが「共通語彙基盤」(IMI: Infrastructure for Multilayer Interoperability) なのです。経済産業省とIPA(独立行政法人 情報処理推進機構)が中心になって、検討と開発が進められているもので、「データを読み書きするための「言葉」をそろえるための基盤」にすることをめざしています。
図1 構造化された語彙の例
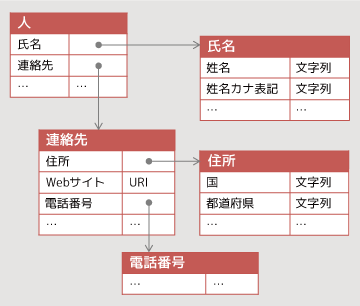
山本このときに必要になってくるのが「語彙」です。ただし、ここでの「語彙」は一般的なイメージとは少し違うものです。ここで言う「語彙」とは、データの項目名や構造、関係性を整理してまとめた用語集のようなものだと考えてもらえれば大丈夫です。
どういうことなのか、「人」を例にとって説明しましょう。ひと言で「人」と言っても、いろいろな情報で構成されています。「氏名」、「性別」などその人自身を示す情報から、「連絡先」や「勤務先」などその人に付随する情報などがあります。さらに、それらの情報は細分化されていて、「連絡先」は「住所」や「Webサイト」、「電話番号」、「住所」は「国」、「都道府県」といった情報で構成されています。
このように、用語の意味、用語同士の関連性を構造化してまとめたものが「語彙」というわけです。この図では一つの用語だけを示しているので単純なツリー構造になっていますが、実際はもっと複雑な構造になります。例えば、「電話番号」は、「人」にも含まれるし、「組織」にも含まれる情報です。要素同士が網目状につながっている状態になります。
…と、ここまでご説明しましたが、なかなか難しいですよね。わたしも1年以上「語彙」と向き合っていますが、いまだに説明するのが難しいと感じています。
山本そうなんです。用語の表記や意味、関係性などを構造化したものを「語彙データ」として蓄積し、それを社会全体で共有することで、オープンデータを利用しやすくしたいと考えています。日立では、共通語彙基盤の開発に向けて、2013年の秋からおよそ1年間、お客さまと一緒に「あるべき姿」を検討してきました。どのような流れで語彙データを活用していこうと考えているのか、図を使って説明しましょう。
図2 共通語彙基盤の概要
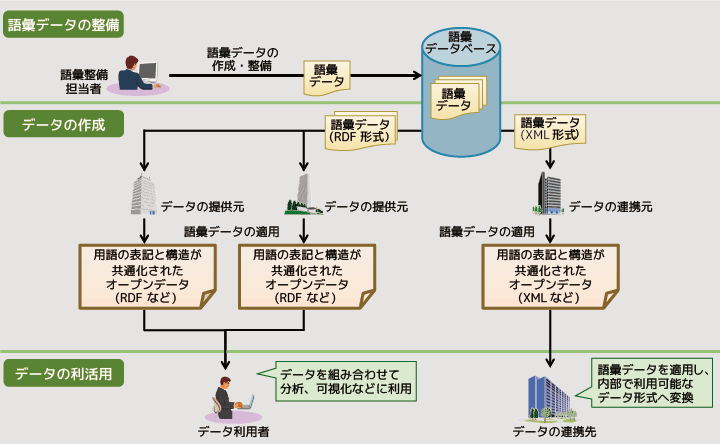
まず、用語の表記や意味などを構造化した「語彙データ」を整備し、語彙データベースに登録します。このとき、ただ登録するだけでなく、ほかの用語との関係性の見直しなどをしながら、語彙データを整備していきます。次に、蓄えられた語彙データを使って、オープンデータや連携用データの用語をそろえます。このとき語彙データは、RDF(Resource Description Framework)やXML(Extensible Markup Language)といった機械処理のしやすいデータフォーマットで表現されます。これらをオープンデータなどに適用することで、自動的に用語の表記や構造を共通化できます。そして、用語のそろったデータを利活用することで、分析や可視化がスムーズにできるようになります。

山本そうですね。最初のうちは共通語彙基盤にかかわる有識者たちがある程度用意しますが、共通語彙基盤の利用範囲を拡大していくためには、各分野から必要な用語を提案してもらって、それらを取り込んでいけることが理想だとお客さまも考えていらっしゃいます。一方的に「この語彙を使ってください」と押し付けるものではなく、社会全体で語彙を育てていく基盤にしていきたいとおっしゃっていますね。
わたしたちも、このご要望にこたえるために、整備するときの「枠組み」となる語彙データの分類から、「中身」になる語彙データのサンプルまで検討しました。検討にあたっては、海外では「語彙データ」の活用が進んでいましたので、現地に出向いて調査をしました。アメリカとヨーロッパに出向いて、有識者と直接意見交換をしたのですが、このプロジェクトでないとお会いできないような方々とお話しすることができて、個人的には貴重な経験になりました。わたし自身、これまでの専門とは違う新しい分野の考え方に触れることができ、勉強になることが多いプロジェクトだったと感じています。
山本共通語彙基盤はさまざまな人が利用する基盤になるため、たった一つの共通集合にするのは難しい…と考えていました。そこで、語彙を3階層に分ける枠組みを設けました。具体的には、みんなが共通して使う「コア語彙」を中心に、複数の分野(ドメイン)で共通して使われる「ドメイン共通語彙」、特定の分野でしか使われない「ドメイン固有語彙」に分けました。この3階層を、「コア語彙」を中心に、「ドメイン共通語彙」、「ドメイン固有語彙」と広がっていく、ドーナッツ型の構成で表現しています。真ん中の「コア語彙」はみんなが共通理解をしている語彙になり、外側に広がれば広がるほど、理解している人が限定される語彙になります。
図3 語彙の分類
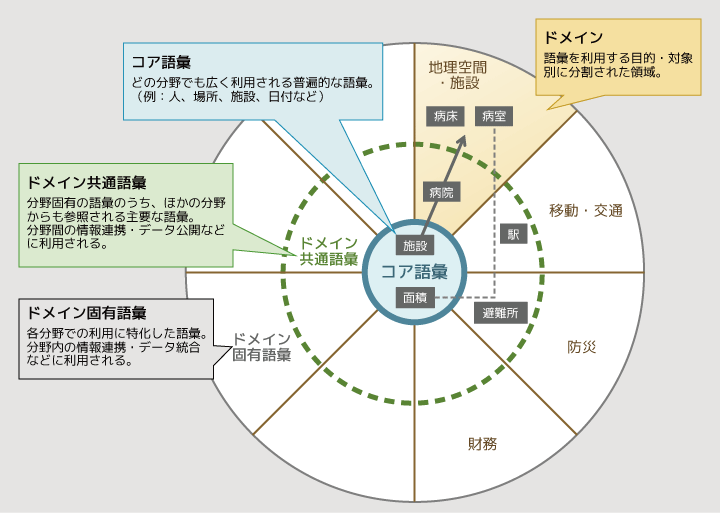
「病院」に関連する語彙を例にとって考えてみましょう。まず、病院を施設としてとらえる場合、「施設」はすべての分野で使う語彙なので「コア語彙」に入ります。一方、「病院」は、すべての分野で使われる語彙ではありませんが、防災などほかの分野からも参照される語彙なので「ドメイン共通語彙」になります。そして、「病室」や「病床」など、その分野の人しか使わないような語彙については、「ドメイン固有語彙」となるわけです。
ただ、「病室」を構成する要素として病室の「面積」がありますが、「面積」という概念はほかのいろいろなものにも共通して使われています。なので、病室の面積を表すときは、ドメイン固有語彙ではなく、コア語彙として定義されている「面積」を使用するというかたちになります。
山本「コア語彙」と「ドメイン共通語彙」のラインナップについて検討したのですが、「どこまで定義するのか」「どの階層に入れるのか」という線引きのバランスがとても難しかったです。「コア語彙」についてはお客さまと一緒に検討したのですが、「ドメイン共通語彙」については、我々が一から検討する必要がありました。ただ、わたしたちは各分野の専門家ではないので、どのような用語が適切なのか判断できません。なので、各分野の専門家をお呼びして意見聴取を行い、その内容をフィードバックするという方式で検討を進めました。今回、4分野の語彙を検討したのですが、各分野で3~4回ずつ意見聴取を行いました。専門家の方の意見や知識を引き出したいのですが、「どのようなテーマで議論すればよいのか」というところでとても頭を悩ませました。意見をまとめるところも大変なのですが、「いかに引き出すか」というところにいちばん苦労しましたね。
山本いちばんの課題は、「語彙」という考え方やメリットを普及させることだと感じています。この基盤を広く活用してもらうためには、できるだけ多くの人に「語彙」の考え方を理解してもらう必要があります。しかし、現時点では、社内でもまだまだ知らない人が多いという状況です。なので、まずは社内から「語彙」の理解を広めようと、定期的に勉強会を実施したりもしているんですよ。

山本そうなんです。日立製作所としても、今回の検討のノウハウを生かして、新しいソリューションや製品ができないかと検討を始めているところです。例えば、組織内で部門ごとにデータの形式が異なっているため、データを活用しづらく、業務効率が悪くなっている…という状況があるとします。それに対して、共通語彙基盤と連携しながら、部門間のデータを一つの形式にそろえて可視化・分析できるようにするアプリケーションやサービスが提供できるのではないかと考えられます。従来のデータ統合の事業と似たかたちで、データの「形式」を統合する、という新しいビジネスが考えられるのではないかと思います。
山本これまでは社外の方と触れ合うことが少なかったので、このプロジェクトはとても良い経験になりました。今回、社外の方々と触れ合う機会に恵まれたことで、わたし自身の意識が大きく変わったと感じています。特に、お客さまと直接議論する場に加われたことが大きかったです。議論の場に参加してみると、改めて「知識」や「技術」の大切さを感じました。今後も知識と技術をさらに向上させて、お客さまと一緒に良いものを作れるパートナーになれるよう励んでいきたいと考えています。

