発話の重なりを含む電話音声を用いた評価で従来法を上回る精度を達成
2019年12月16日
株式会社日立製作所
日立は、会議音声認識システムの精度向上をめざし、発話の重なりを含む音声から学習したニューラルネットワークにより、音声の重なりがあっても、各人の発話の始めから終わりまで(以下、音声区間)を検出するEnd-to-End*1話者ダイアライゼーション*2技術を開発しました。従来は、各人の音声が重ならないことを前提とした音声認識システムが用いられてきましたが、本技術の適用により、一つのマイクで録音した、発話の重なりがある自然な会話音声の認識精度が向上します。今回、一般的な電話音声データセットを用いた検証では、音声の重なりを考慮しない従来法を上回る精度を達成し、さらには、発話の重なりが多いシミュレーション音声でも、ダイアライゼーション誤り率*3(以下、誤り率)が極めて小さくなることを確認しました。今後、日立は、本技術を会議音声の書き起こしサービスや音声対話サービスなどに活用することで、労働力不足の解消や労働生産性の向上に貢献していきます。
本方式では、ニューラルネットワークの出力として、話者の人数分の出力層を用意することで、重なりを含んだ音声に対応することができます。しかし、出力される話者の順序は決まっていません。この性質は、ニューラルネットワークの学習を妨げる要因となります。そこで今回、学習データにおける出力の順序に依存せずにニューラルネットワークを最適化できる「パーミュテーションフリー学習法」を適用しました。パーミュテーションフリー学習では、学習データにおける出力の順序の組み合わせを全て評価し、最も誤りが小さくなる出力順序に基づいてニューラルネットワークの更新を行います。これにより、初めて一つのニューラルネットワークで重なりを含んだ音声に対応する、End-to-End型の話者ダイアライゼーションを実現しました。
End-to-End話者ダイアライゼーション方式では、音声の時系列信号を入力し、音声区間の時系列を出力します。通常、時系列処理を行う場合には、過去の入力の記憶を更新しながら出力を行う再帰型ニューラルネットワーク(Recurrent Neural Network)を用いることが標準的です。しかし、話者ダイアライゼーションでは、次の発話までに時間が開いた場合も、同じ話者特徴を持つか異なる特徴を持つかを識別する必要があり、再帰型ニューラルネットワークの記憶に基づく識別には限界がありました。そこで今回、各時刻の特徴を全時刻の特徴と比較し、特徴間の類似性に基づいてより識別しやすい特徴に変換する自己注意機構を用いました。これにより、再帰型ニューラルネットワークでの性能を大幅に上回ることが出来ました。
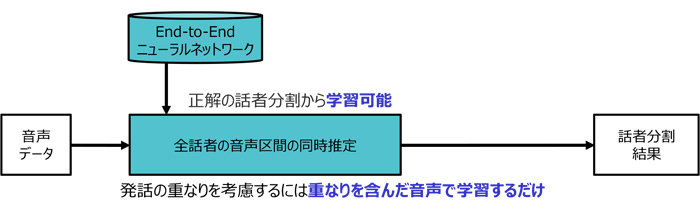
図1 開発したEnd-to-End話者ダイアライゼーション方式
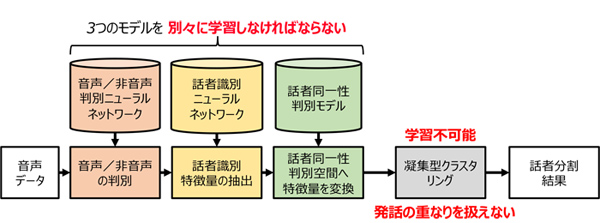
図2 従来の話者ダイアライゼーション方式
関連リンク


