ビッグデータ時代のデータ分析で、成功・失敗をわけるものは何か。
![]()
データ分析がうまくいかない原因は、「データの下準備ができていない」ことと、「反復プロセスを継続できない」ことだとわかった。では、これらを解決してくれる仕組みはないのだろうか。
それが、データパイプラインという構想である。
企業内に散在するシステムは、扱うデータこそ異なるものの、データの下準備では同じような作業プロセスを経ている。そこに注目し、データの収集、変換・統合、ブレンドといった共通作業を一本化した構想がデータパイプラインである。この最大の特長は、データ分析における「手作業」を減らせること。最も手間が掛かっているデータの下準備を効率化することで、データ利活用が促進できるのだ。
図にすると、次のようになる。
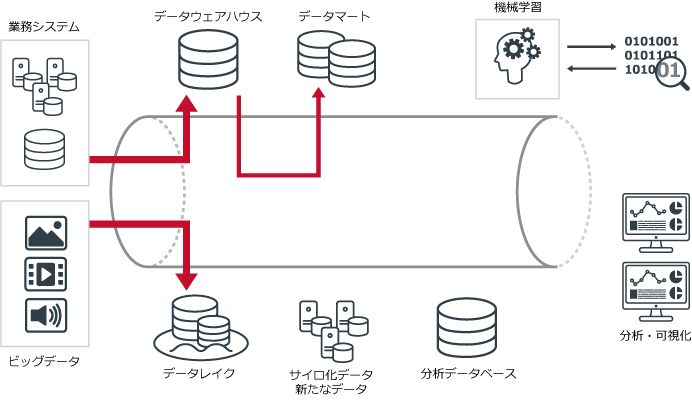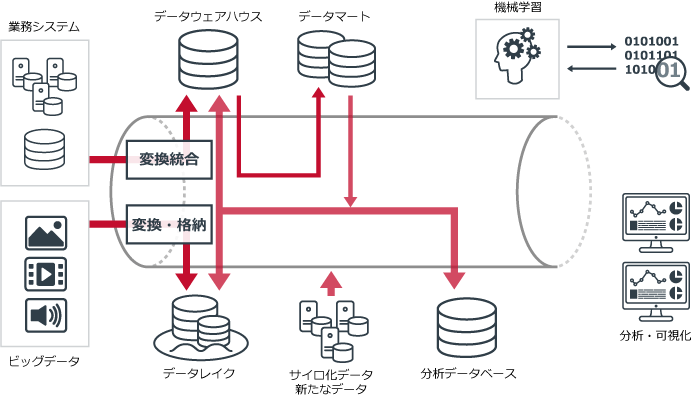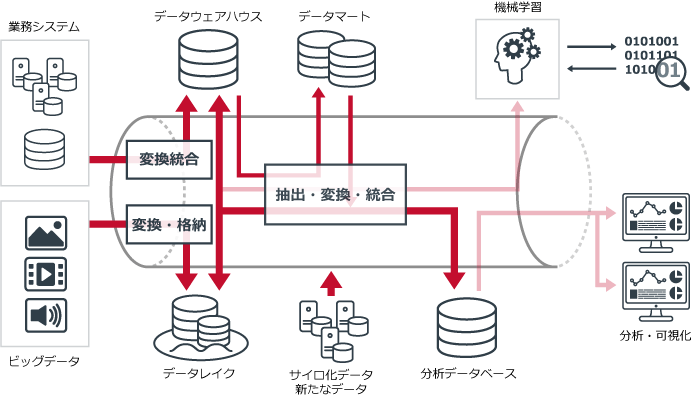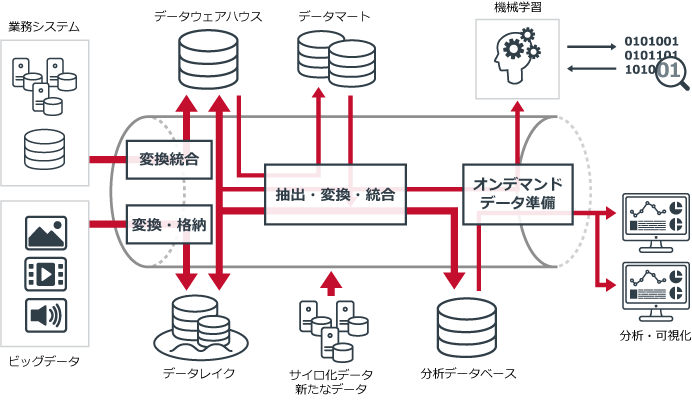
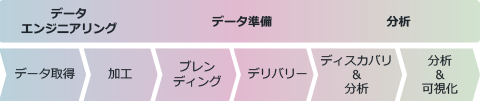
データパイプラインで、各工程は次のように改善される。
サイロ化されていた業務システムのデータは、容易にデータ形式を変換できるようになる。すべてのデータが簡単に統合できるようになるため、手作業の手間は劇的に軽減。また、これまでのようにデータソースが把握できない問題も解消され、必要なデータはすべて取り出せるようになる。ビッグデータを管理する環境も用意されているため、さまざまな非構造化データ・半構造化データも簡単に格納できるようになる。
既存の業務データとビッグデータを抽出して、これらのデータをブレンディングすることが容易になる。これまでのように、限られたデータソースから分析用データを準備するのではなく、複数のデータソースによるブレンディングが可能となるので、分析の幅が拡大。より有用な洞察へとつながり、ビジネスにおける競争優位の獲得にいかすことができるようになる。構築後に、新たにサイロ化されたデータが発生しても、簡単に変換・統合できるようになるため、増え続けていくデータの管理を心配する必要もなくなる。
分析用のデータが容易に作成できるようになることで、データサイエンティストからのデータ要求や、多様化する分析ニーズにも迅速に対応できるようになる。その結果、分析現場へ迅速に分析用データを供給することが可能となる。
データパイプラインの優れた点は、これらの工程をあたかもパイプラインのようにシームレスにつなぎ、データ発生源から分析現場までのデータフローを全社で共有できることにある。これまでの運用のように、工程ごとに別々のツールを導入したり、手作業でのデータ共有に苦労したりすることがなくなり、全工程をスムーズに効率的に実施できるようになるのだ。
POINT
データパイプラインとは、例えるなら大量データの交通整理である。このデータパイプラインにデータを要求すれば、大量かつ絶え間なく流れているデータを交通整理してくれ、タイムリーに欲しいデータを取得でき、「データ分析」と「データの下準備」という反復プロセスが可能になるのである。まさに、データ分析に必要不可欠な基盤ではなかろうか。
優れた分析を可能にしてくれる、データパイプライン。これを部門最適にとどまらず、全社横断で構築することで、データ分析はより価値あるものとなり、その分析結果を新ビジネスの創生や業務の改善にいかすことで、競争優位性の獲得が期待できるであろう。
データパイプラインは、優れたデータ分析を可能とする理想的な構想である。しかし、見よう見まねで構築しても決して成功はしない。次の3つの条件を満たしたデータパイプラインを構築することが、データ分析の成功へとつながる。
