システム運用に役立つ情報を提供システム運用ハック
オブザーバビリティ

2025年1月22日公開
企業では、サービスを提供するシステムや基幹系システムなど複数のシステムを運用しており、ビジネスに影響を及ぼすシステム障害の検知、対策をスムーズに行うことは、多くの企業にとって重要な課題の1つです。
ここでは、統合システム運用管理 JP1を活用して、複数のシステムを運用していても、システム障害の検知および調査を効率よく行う方法をご紹介します。
【使用するツール】
または
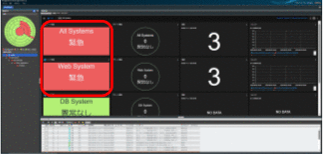
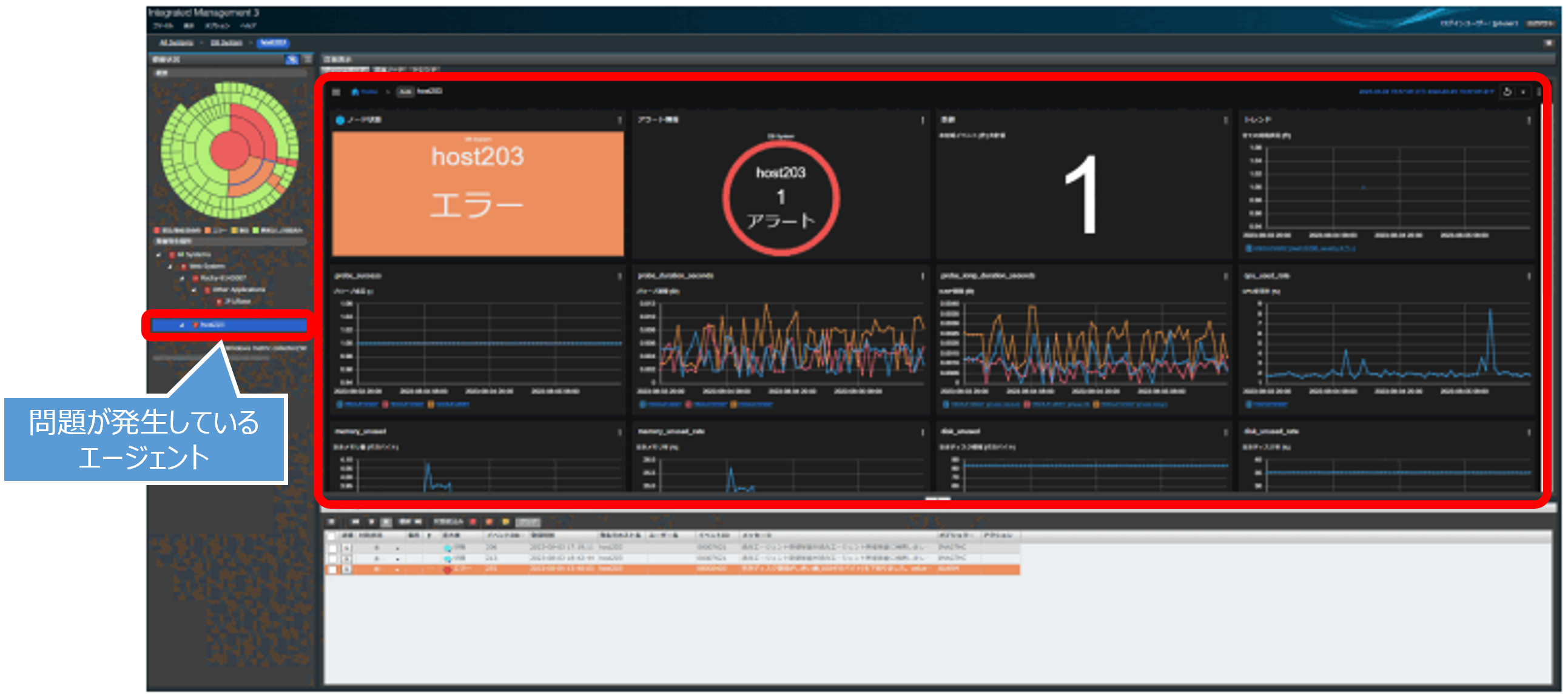
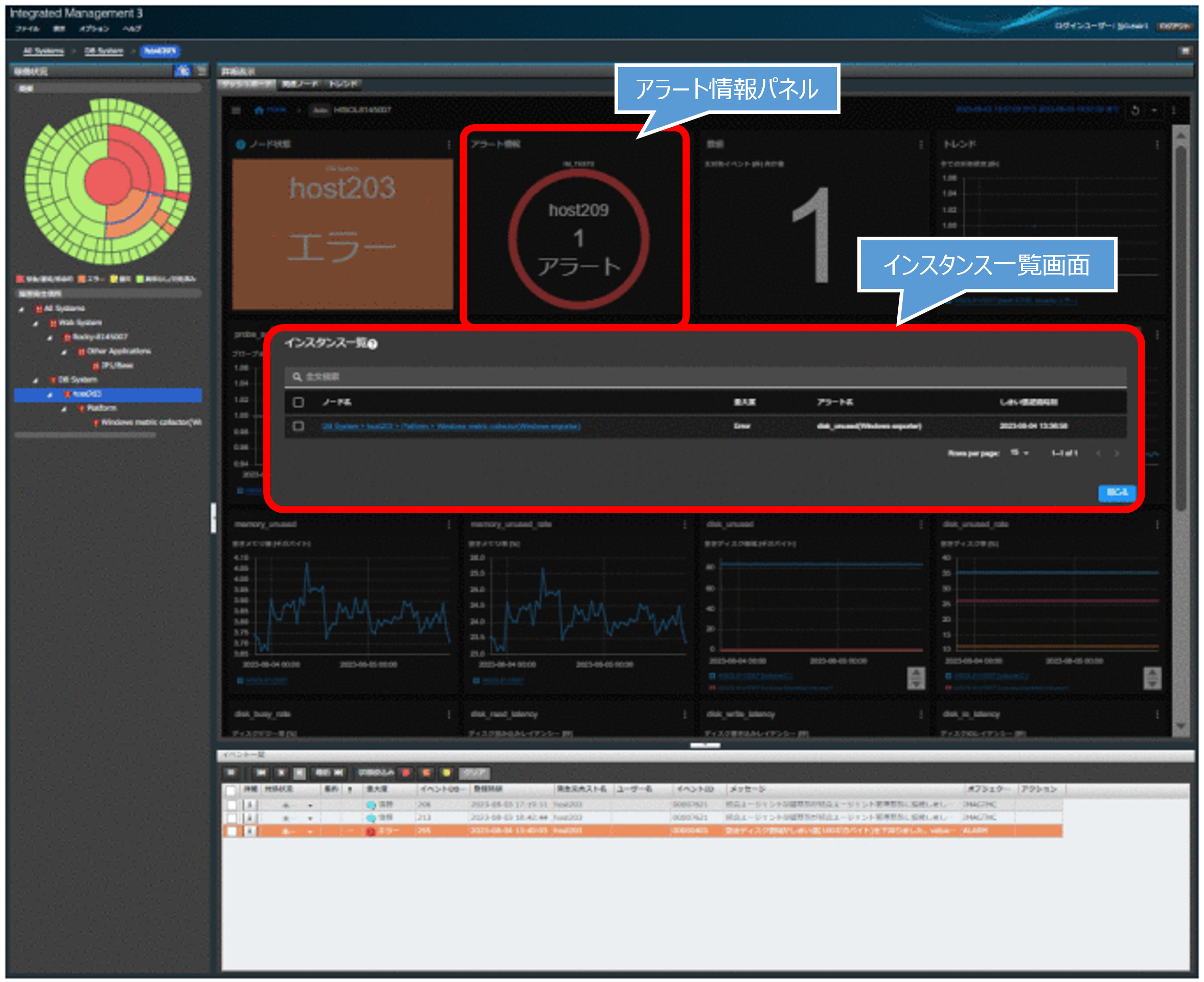
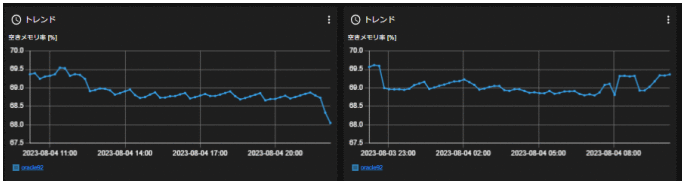
このように、JP1の統合オペレーション・ビューアーでは複数システム全体を対象にして、発生した障害を視覚的に素早く把握でき、問題が発生したエージェントの調査も効率よく進めることができます。
最後までお読みいただきありがとうございました。


