

一般的に実行頻度が高く、データアクセス量が多い検索では、その処理時間のほとんどをストレージI/Oの処理時間で占められていると言われているんだ。大量データになればなるほど、その傾向は顕著になる。そこで、Hitachi Advanced Database では、大量データの検索時にストレージI/Oの処理時間の短縮化がはかれるように「非順序実行原理」を採用して高速化を実現しているんだ。では、この「非順序実行原理」を「くす玉」割りに例えて解説してみよう。
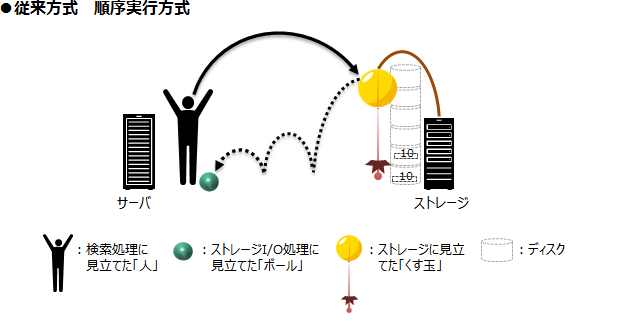
ディスクストレージで管理しているデータに「10」と書いてあるデータが何件あるか知りたいと仮定しよう。この処理プロセスを、検索処理に見立てた「人」がストレージI/O処理に見立てた「ボール」を投げて、ストレージに見立てた「くす玉」を割ることで、データ件数分の「プレゼント」をゲットできるようにしたのが「くす玉」割りの例だ。
従来の順序実行方式では、投げた「ボール」が戻ってくるまで検索処理に見立てた「人」は「ボール」が投げられないから、待ち時間は長くなるし、全てのディスクを総なめしないとデータ検索は完了しないから、該当するデータの件数を知る時間も長くなる。
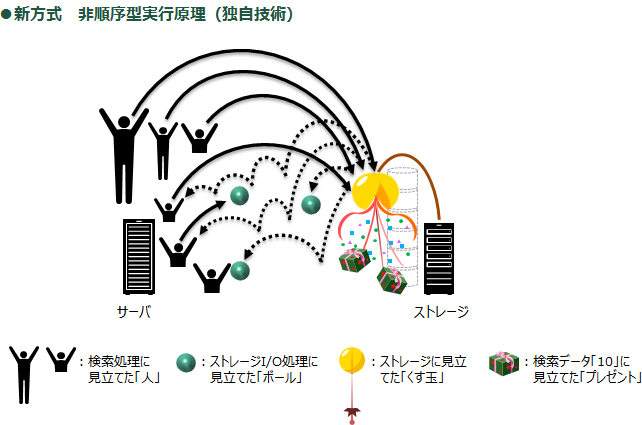
ところが、新方式「非順序型実行原理」では、検索処理を自動分割して高多重するから、検索処理に見立てた、たくさんの「人」がストレージI/O処理に見立てた「ボール」を一斉に投げて「くす玉」に当てることができるんだ。他人が投げた「ボール」を拾って使っても構わないから、待ち時間は短くなるし、データ検索が完了する時間も短くできる。
このように、従来の順序実行方式と比べると、「非順序型実行原理」の方が「くす玉」割りにかかる時間が短くなるので「くす玉」に隠れている「プレゼント」も早くゲットできる訳だ。
実際、大量データの検索処理でサーバ-ストレージ間でやりとりされる処理数は、数千~数万個あるといわれている。だから、ストレージI/Oの処理時間が短縮できれば、検索処理の高速化にもつながるという訳だ。
